
Releasing FedLLM: Build Your Own Large Language Models on Proprietary Data using the FedML Platform

FedML AI platform is democratizing large language models (LLMs) by enabling enterprises to train their own models on proprietary data. Today, we release FedLLM, an MLOps-supported training pipeline that allows for building domain-specific LLMs on proprietary data. The platform enables data collaboration, computation collaboration, and model collaboration, and supporting training on centralized and geo-distributed GPU clusters, as well as federated learning for data silos. FedLLM is compatible with popular LLM libraries such as HuggingFace and DeepSpeed, and is designed to improve efficiency and security/privacy. To get started, FedML users & developers only need to add 100 lines of source code. The complex steps of deployment and orchestration of training in enterprise environments are all handled by FedML MLOps platform.
Outline
- Why Build Your Own Model?
- FedML: Democratizing LLMs via Open and Collaborative MLOps
- Releasing FedLLM: Building Your Own Large Language Models on Proprietary Data
- How Does FedLLM Work? Only 100 lines of source code for customizing any open LLMs
- Get Started Today
- What's Next?
- About FedML Inc.
Why Build Your Own Model?
ChatGPT and GPT-4, advanced large language models (LLMs) created by OpenAI and Microsoft, have revolutionized the way we learn, explore, and work. The human-like generative ability of these models has ushered in a new era of foundational models, which are unlocking new possibilities and driving innovation across consumer and business use cases, from language and vision to robotics and reasoning.
Despite public and open source LLM’s impressive capabilities, many customers have expressed their preference for owning their models to develop higher quality models for their domain-specific applications. This preference is driven by several concerns:
- Privacy should not be compromised. The state-of-the-art models can only be accessed by general-purpose black-box APIs. These APIs raise privacy concerns for companies when transmitting data to a centralized LLM provider. For instance, Samsung reportedly leaked its own secrets through ChatGPT, highlighting the risks associated with such APIs.
- Proprietary and trained models are important IP. For businesses, the problems and datasets that can most benefit from AI tend to be sensitive and proprietary. This rules out fine-tuning a public model, and therefore business would best be handled leveraging fine-tuning on an internally deployed model, or models deployed on silos within the business’s firewall.
- Cost concern. Currently, the training of LLMs needs thousands of GPU nodes costing billion-level USDs (e.g., OpenAI scales Kubernetes to 7,500 GPU nodes to train ChatGPT/GPT-4). Models may need to balance different trade-offs, such as compromising the model performance slightly to reduce the cloud cost. Owning models allows customers to fine-tune and retrain them conveniently. For instance, they may remove redundant model parameters to achieve high performance for a domain-specific task while minimizing cloud cost.
FedML: Democratizing LLMs via Open and Collaborative MLOps
As discussed above, LLMs and foundation models need to be accessible to all companies and customizable according to their needs and on their proprietary data. LLM training costs must also be within reach and not at cost levels only affordable by a few big tech companies (e.g., Microsoft, Google). Ultimately, democratizing LLMs would provide numerous advantages for enterprise business users, greatly enhancing a business's ability to work with large models in terms of model scale & performance, privacy, efficiency, cloud costs, and labor costs
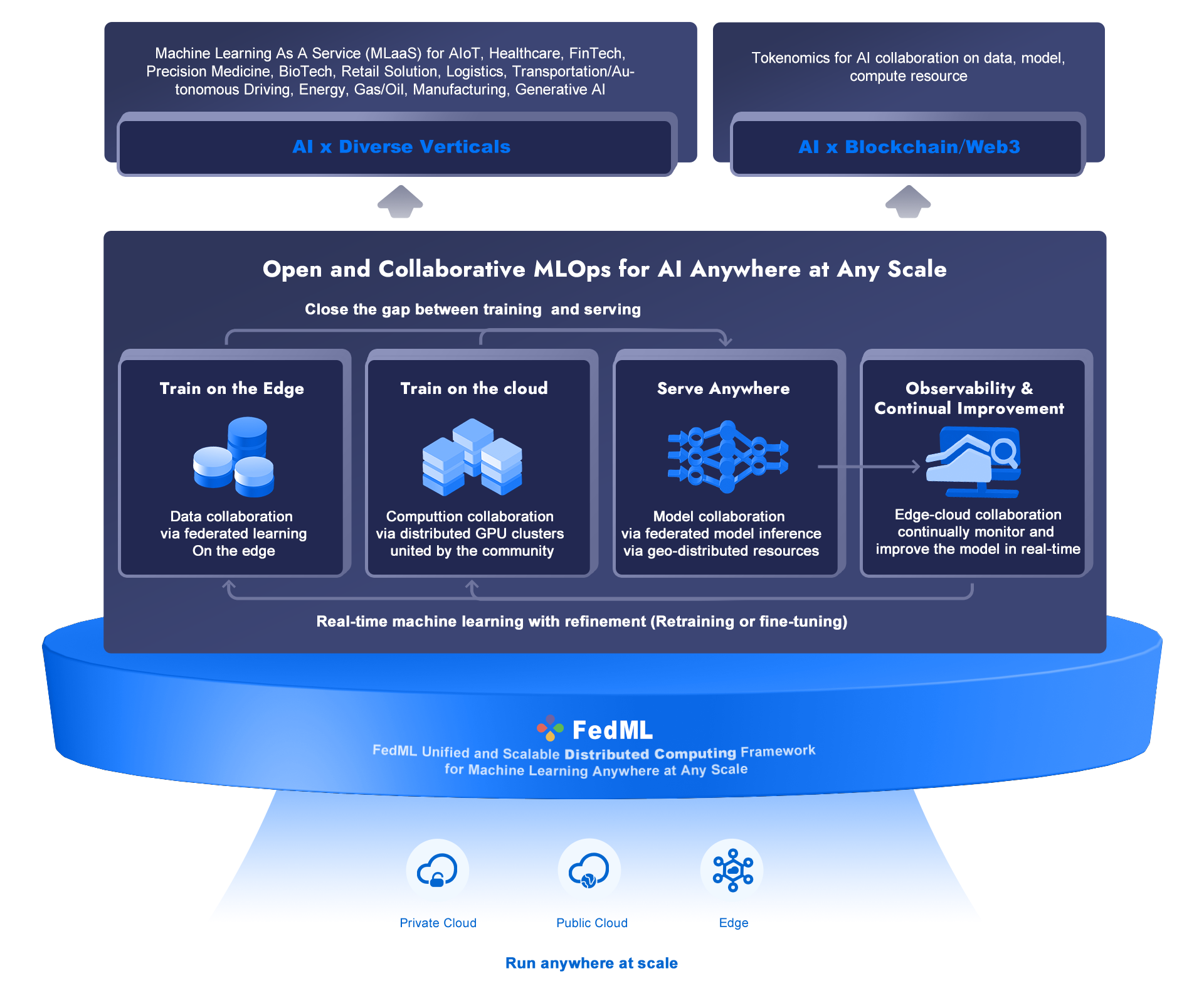
As an end-to-end MLOps system (shown in Figure 2), FedML AI platform (https://fedml.ai) aims to provide a foundation for LLM democratization. Besides the capability of training, serving, and observability for LLMs, the FedML AI platform further brings new value:
Data Collaboration - Enabling the Training of LLMs on domain-specific proprietary data. The general-purpose LLMs ChatGPT and GPT-4 are trained on a huge amount of text published and annotated by humans. In many verticals (such as healthcare, FinTech, legal, and automotive industries), ChatGPT might not work well. Enabling enterprises to train their models on their proprietary data can achieve better performance while preserving privacy. In some cases, when the dataset is scattered across silos, FedML federated learning training pipeline “Train on the Edge” will handle it in a secure and scalable manner.
Computation Collaboration - Harnessing fragmented computing resources. LLM pre-training is a luxury affordable only for a few big tech companies (e.g., Microsoft, Google) due to the high investment in computing power. Enterprises in diverse verticals cannot afford thousands of GPU nodes that cost billions of dollars. A more cost-efficient way to leverage GPU resources would be to build a sharing mechanism across organizations. FedML enables this via the “Train on the Cloud” platform, which can schedule training jobs to geo-distributed CPU/GPU networks. Such collaboration in computation can reduce the financial burden of buying a large number of GPU nodes in a single organization.
Model Collaboration - Serving the model in a federated manner with observability support. Serving large foundation models is also challenging. Compared to other MLOps, FedML pioneers the idea of federated model inference via geo-distributed cloud computing resources. When inference requests are sent to the inference endpoints, the master node would route the request to decentralized edge nodes hosted by GPU vendors who can share GPU idle time. Such a model serving platform can provide better service reliability and cheaper cloud cost.
In short, by enabling collaborative and privacy-preserving machine learning infrastructure, enterprises and their AI developers can leverage LLMs and foundation models, and further, customize those LLMs on their proprietary data affordably, efficiently, and securely.
Introducing FedLLM: Building Your Own Large Language Models on Proprietary Data
To show the power of FedML AI platform in supporting LLM and foundation models, our first release is FedLLM, an MLOps-supported training pipeline to build the enterprise’s own large language model on proprietary data. The example code can be found at https://github.com/FedML-AI/FedML/tree/master/python/spotlight_prj/fedllm.
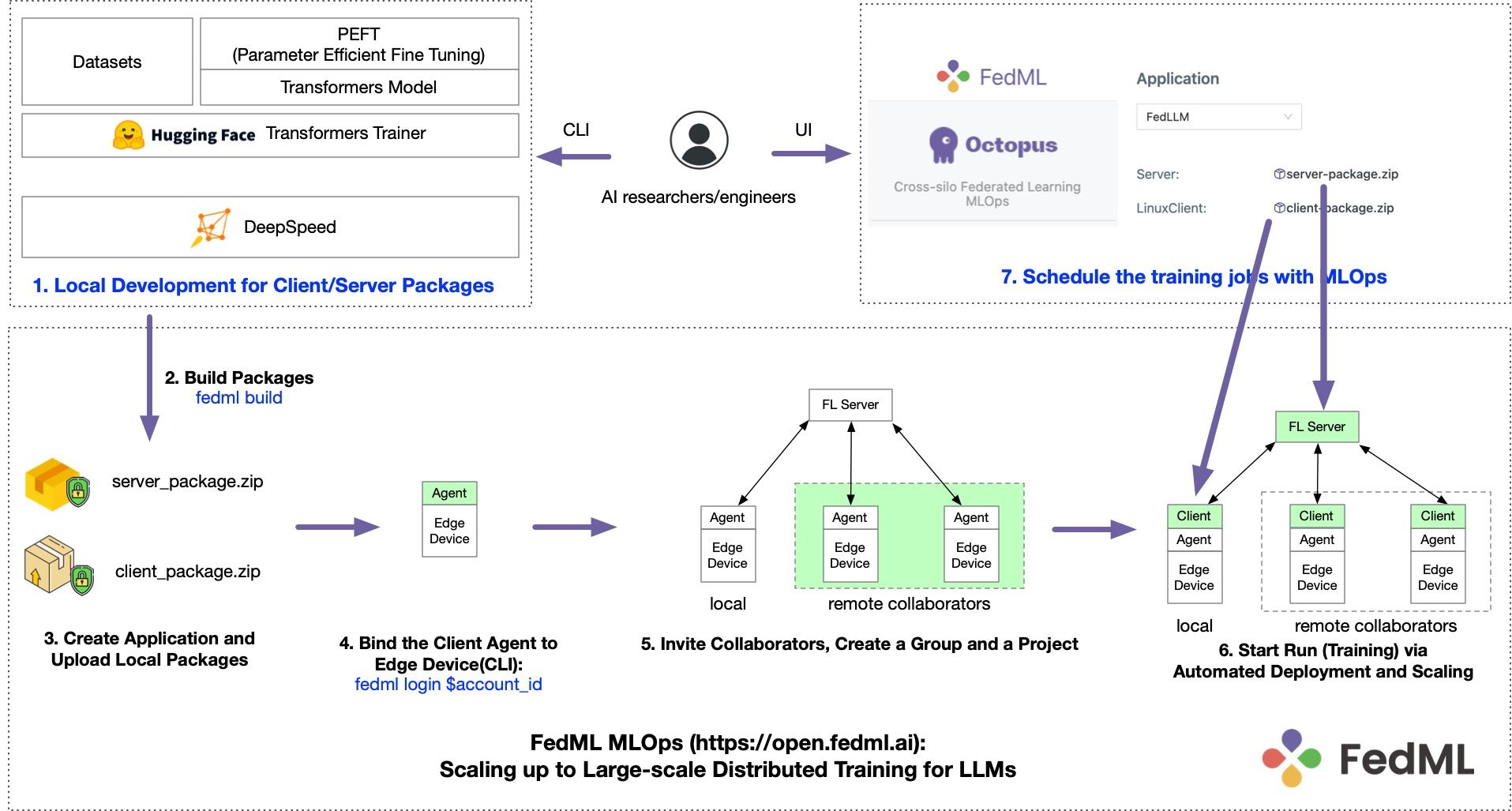
The entire training pipeline of FedLLM is illustrated in Figure 3. FedLLM can do training in both centralized and geo-distributed GPU clusters, as well as in a federated learning manner for data silos. For a specific siloed GPU cluster, FedLLM leverages existing open-source LLMs and popular frameworks for local training:
- The model definition and pre-trained weights are from EleutherAI's pythia's 2.8B, 7B, and 12B versions. We refer to Hugging Face's transformers as the reference implementation. FedLLM is also a model-agnostic framework where enterprises and developers can plug-in any LLMs.
Update July 2023: FedLLM supports Meta's Llama 2 - For efficient training, FedLLM supports parameter-efficient training methods such as LoRA. Its reference implementation is from HuggingFace's peft.
- For a single standalone trainer, its training/evaluation code is based on Trainer in the transformers library.
- The distributed training framework on a specific GPU cluster is handled by DeepSpeed. We also enable Zero3 to reduce memory costs for a single GPU. By enhancing the compatibility between FedML and DeepSpeed, FedLLM can run the training jobs across different geo-distributed clusters.
Three creative ways of using FedLLM platforms: supporting both centralized and federated training
Note that FedLLM stands for “foundational ecosystem design for LLM”, not just “federated learning for LLM”. Here are three creative ways of using FedLLM platforms:
- AI Foundry. AI practitioners do not need to deal with the complexity of a distributed training system. Practitioners just need to upload proprietary data and expect the trained model as output or a served API for product usage. FedLLM will leverage the FedML platform to handle the training job in a dedicated GPU cluster in a single data center, where DeepSpeed is used for efficient parallelism in the multi-node multi-GPU setting. In this case, FedML serves as the backend to handle all engineering work, including serving as the scheduler to match the cost-efficient resources to accelerate the training, the optimizer to train faster, the observability to enhance operation and maintenance, the quality controller to make the training robust even it failed in the middle.
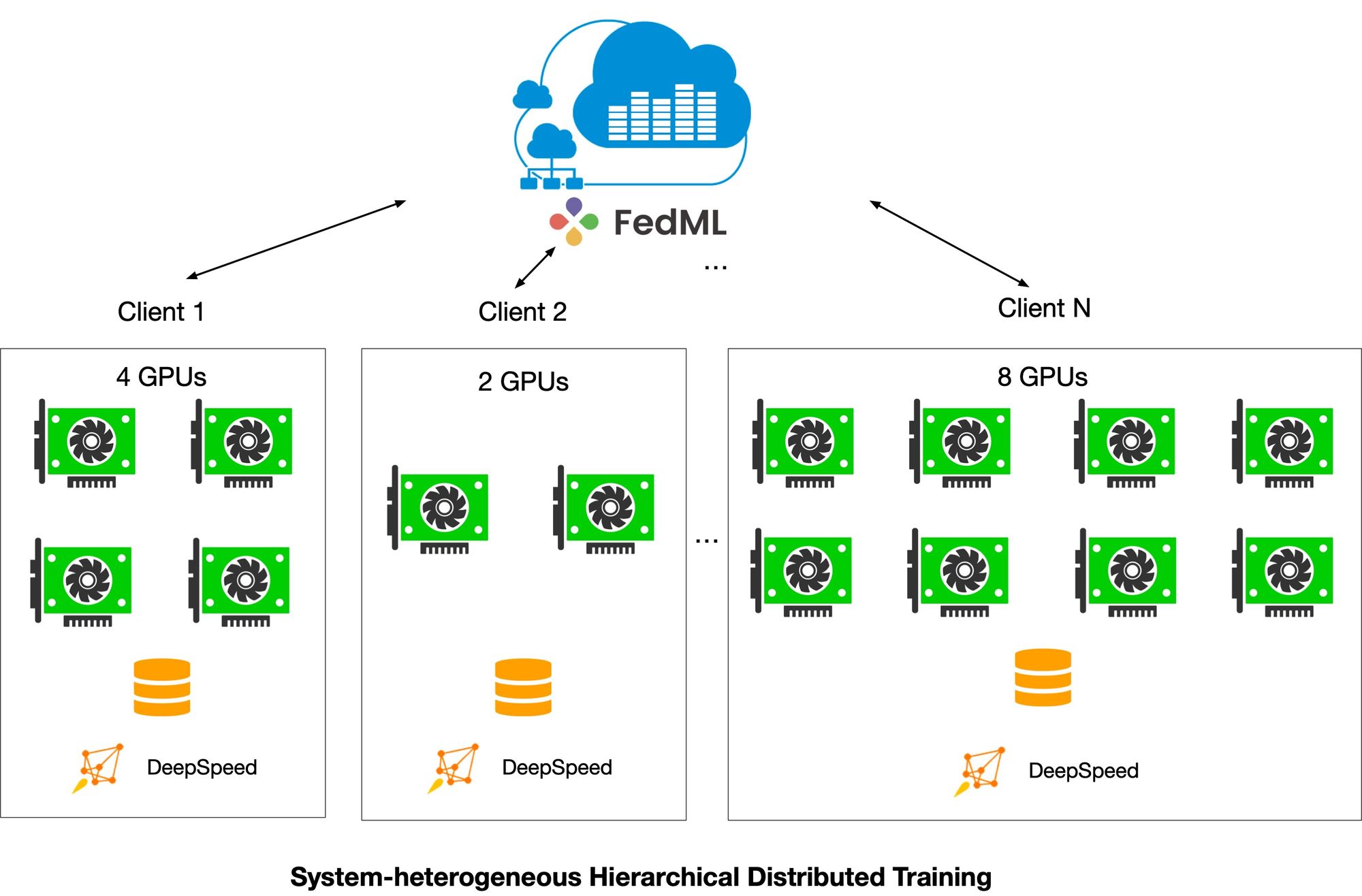
Connecting Isolated computing resources. As illustrated in Figure 4, FedLLM can leverage FedML capability to run training or serving jobs in a geo-distributed cluster. This is helpful when a single data center does not have enough GPU nodes to handle the training. Rather than buying a brand new GPU cluster for distributed training, Enterprise can merge their existing isolated GPU resources to train large LLM. The communication cost is not a concern given that FedML platform leverages many optimization methods to reduce the communication cost, such as local SGD, parameter-efficient training, and communication compression.
Federated learning for distributed data. FedLLM has federated learning capability as it leverages FedML's federated learning platform. And it’s been shown that model performance is significantly enhanced when one learns from datasets on disparate data silos. Federated learning enables machine learning on that distributed data by moving the training to the data, instead of moving the data to the training. Governance of the source data is therefore maintained locally, alleviating privacy & data migration concerns & costs inherent in traditional machine learning. FedLLM enables DeepSpeed as a client.
Our Pioneering Work FedNLP - Federated Learning for Natural Language Processing
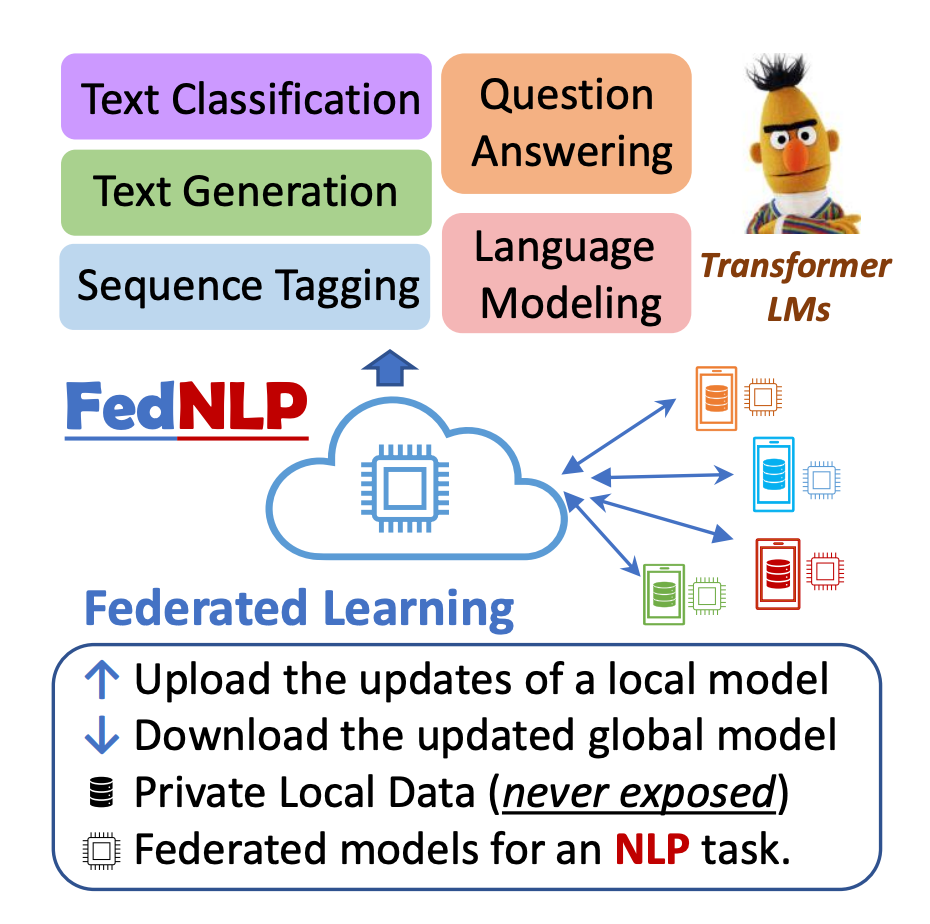
FedML is not new to text processing or Natural Language Processing. Two years ago, we launched FedNLP, to enable a federated learning approach to traditional natural language tasks such as text classification, sequence tagging, and Seq2Seq. We proposed a universal interface between Transformer-based language models (e.g., BERT, BART) and FL methods (e.g., FedAvg, FedOPT, etc.) under various non-IID partitioning strategies. Our extensive experiments with FedNLP provided empirical comparisons between federated learning methods and help us better understand the inherent challenges. Our initial work with FedNLP spurned us to continue development for NLP and the recent advances in LLMs. Now the upgraded FedLLM supports both centralized training and federated training.
A Federated LLM Use case
The following simplified diagram shows a business scenario for leveraging LLM in a traditional federated learning use-case where data sovereignty regulation requires that local data stays local. Local data stays local, and only the model parameters or weights data flows to and back from a central Federated server. This particular example envisions a Chat type of application that incorporates training from local data as well as the benefits of fine-tuned training that the federated server has built by leveraging the training from other locations. The chat app is just for example and can be replaced by other applications that leverage the LLM model's insights. Ultimately, this arrangement brings collaborative intelligence to all locations.
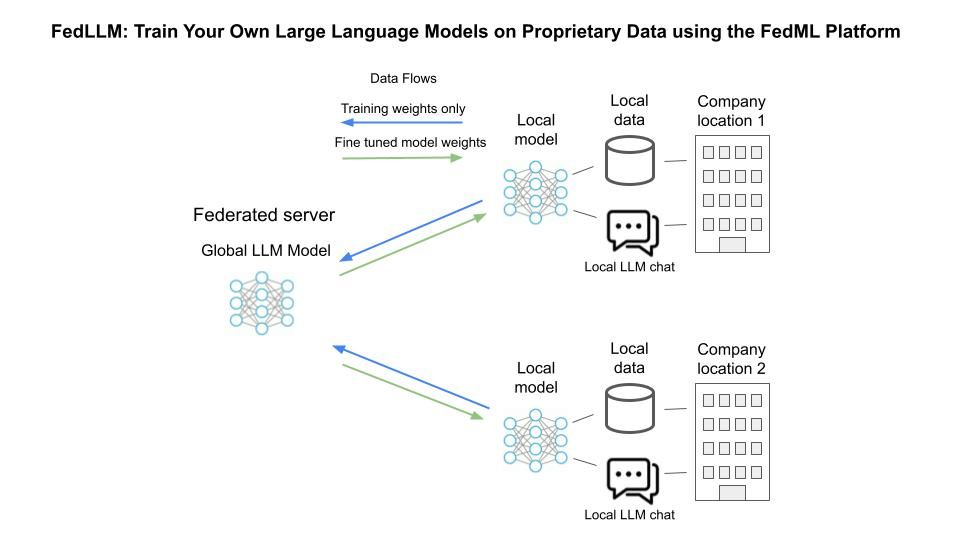
For example, imagine a medical business scenario where there are numerous data centers that are not visible to each other, but there is a desire to use a large language model to train on local medical symptoms and diagnosis and treatment results. Only the training weight data is shared with a central server, where fine-tuning takes place, and an improved model is distributed to each location, thereby helping any medical location to quickly identify more comprehensive & potentially life-saving diagnosis options.
How Does FedLLM Work?
Easy to Learn: Only 100 Lines of Source Code
We are open-sourcing a simple and clean source code that only has less than 100 lines of source code to showcase our FedLLM platform. The code snippets are as follows.
from collections import OrderedDict
import fedml
from peft import get_peft_model_state_dict, set_peft_model_state_dict
from transformers import Trainer
class LLMTrainer(fedml.core.ClientTrainer):
def __init__(self, model, args, tokenizer):
super().__init__(model, args)
self.tokenizer = tokenizer
self.model = model
def get_model_params(self) -> OrderedDict:
return OrderedDict(get_peft_model_state_dict(self.model.cpu()))
def set_model_params(self, model_parameters) -> None:
set_peft_model_state_dict(self.model, model_parameters)
def train(self, train_data, device, args) -> None:
trainer = Trainer(...) # build trainer
trainer.train()
class LLMAggregator(fedml.core.ServerAggregator):
def __init__(self, model, args, tokenizer):
super().__init__(model, args)
self.tokenizer = tokenizer
self.model = model
self.trainer = Trainer(...) # build hugging face trainer here
def get_model_params(self) -> OrderedDict:
return OrderedDict(get_peft_model_state_dict(self.model.cpu()))
def set_model_params(self, model_parameters) -> None:
set_peft_model_state_dict(self.model, model_parameters)
def test(self, test_data, device, args) -> None:
self.model = self.model.to(device)
self.trainer.evaluate(test_data)
self.trainer.save_model()
if __name__ == "__main__":
# init FedML framework
args = fedml.init()
# init device
device = fedml.device.get_device(args)
# build your model, tokenizer and dataset
tokenizer, model = ...
train_dataset, test_dataset = ...
dataset_dict = ... # convert dataset object to federated format
# FedML trainer
trainer = LLMTrainer(model=model, args=args, tokenizer=tokenizer)
aggregator = LLMAggregator(model=model, args=args, tokenizer=tokenizer)
# start training
fedml_runner = fedml.FedMLRunner(args, device, dataset_dict, model, trainer, aggregator)
fedml_runner.run()As we can see from the code above, ML developers only need to write the model, dataset, and trainer in the same way as a stand-alone program and then pass it to the FedMLRunner object to launch the training jobs in a complex GPU cluster. The complete example code can be found at FedLLM GitHub: https://github.com/FedML-AI/FedML/tree/master/python/spotlight_prj/fedllm
Not Reinventing the Wheels: Compatible with Existing Popular Machine Learning Libraries
We built the FedML-powered FedLLM application to be seamlessly integrated with popular LLM libraries such as HuggingFace and DeepSpeed. This largely reduces the burden for beginners to learn and implement the efficiencies built-into these new frameworks, and ensures that the implementation is up to date based on ML’s innovative open source ecosystem. FedML team also keeps optimizing these frameworks from the perspective of efficiency and security/privacy.
No Worry about Communication Overhead
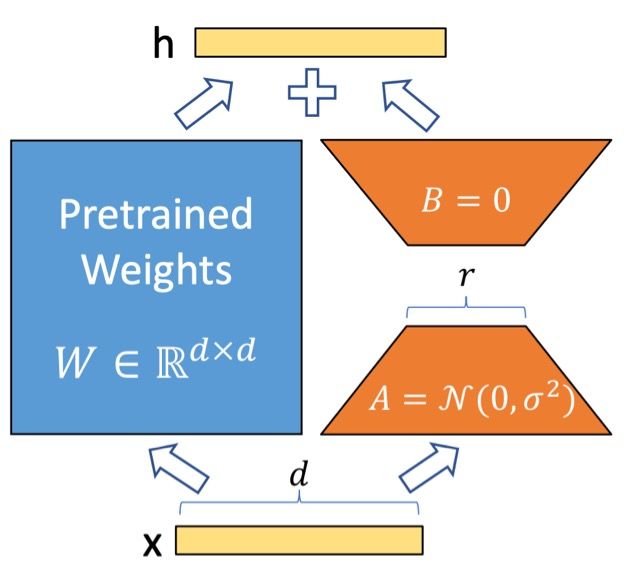
Fine-tuning large-scale LLMs is often prohibitively costly. To address this problem, Parameter-Efficient Fine-Tuning (PEFT) methods only fine-tune a small number of (extra) model parameters, thereby greatly decreasing the computational and storage costs. One of the typical PEFT methods is LoRA, Low-Rank Adaptation, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, as shown in the figure above. In a geo-distributed training setting, only exchanging the trainable parameters significantly reduces the communication cost. We summarize the cost in the following table. We find that modes that initially have up to 12B parameters always become less than 10M (which is less than 1% of the initial parameter count). This communication overhead is very trivial compared to the entire training time.
| Model | Num. params | Num. LoRA params | Trainable % | LoRA's rank r |
| Pythia 2.8B | 2.8B | 2.6M | 0.09% | 8 |
| Pythia 6.9B | 6.9B | 4.2M | 0.06% | 8 |
| Pythia 12B | 12B | 5.9M | 0.05% | 8 |
Simplifying the Orchestration with MLOps Support
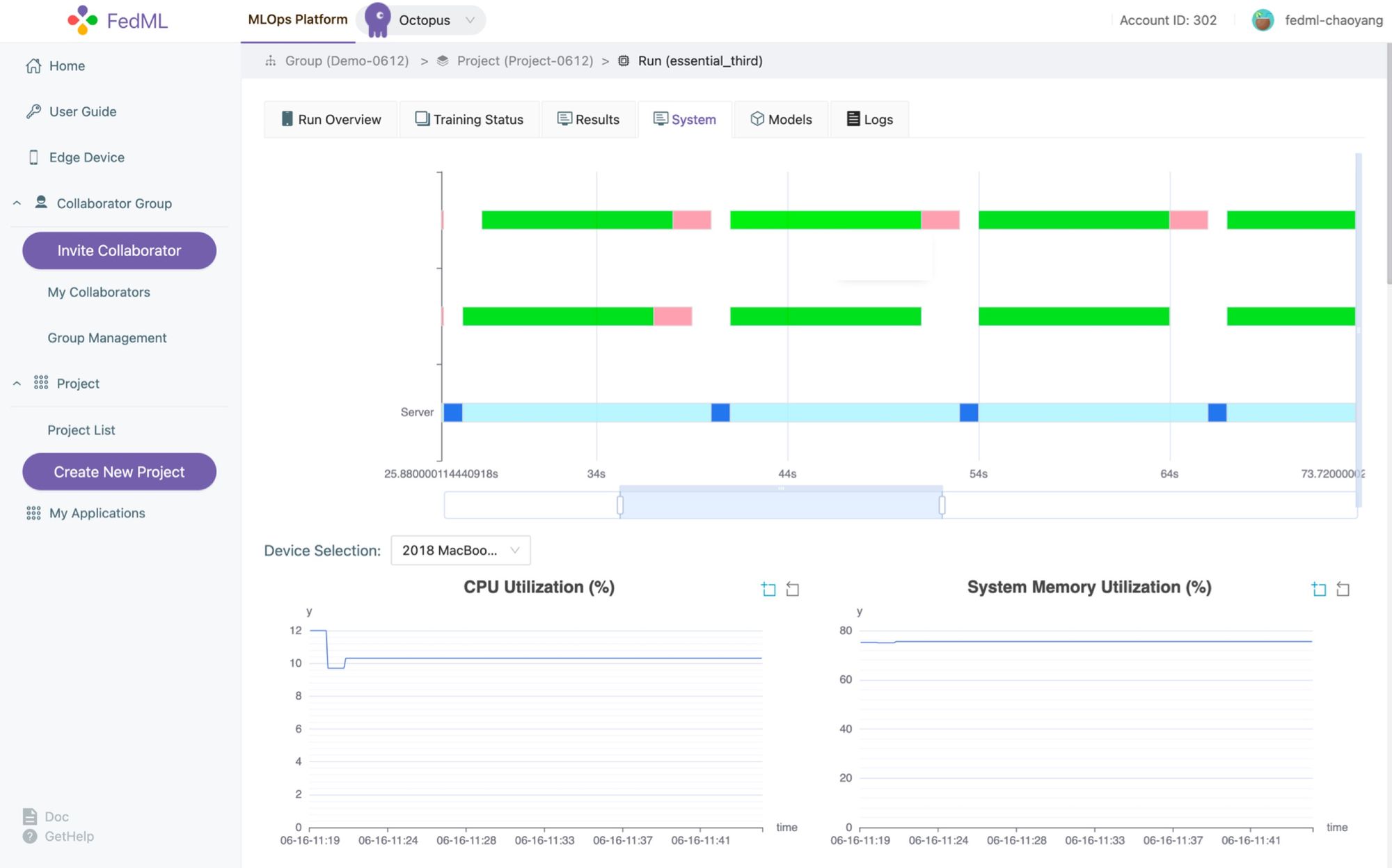
We provide a simplified user experience for orchestration in distributed GPU/data networks with MLOps support. Figure 8-10 show how we build the GPU device group, select the training device, and experimental tracking capability. For more details, please refer to the comprehensive introduction of the FedML AI platform: https://medium.com/@FedML/fedml-ai-platform-releases-the-worlds-federated-learning-open-platform-on-public-cloud-with-an-8024e68a70b6
Get Started Today
Please visit our Github page at https://github.com/FedML-AI/FedML/tree/master/python/spotlight_prj/fedllm and check README.md to have a try. If you find any issues, please join our Slack or Discord discussion.
We understand it’s hard to cover all details in a single blog. Thus FedML team also plans to host a webinar soon for you to discover how you can harness LLMs for your organization. Please subscribe to our blog notifications and we’ll let you know details. Also, feel free to email us at https://www.fedml.ai/contact with thoughts, needs, and suggestions.
What's Next?
FedML team will keep iterating the ML infrastructure to enhance the FedLLM training pipeline. Some of those enhancements will come through three projects we’re currently developing:
FedML Cheetah: A decentralized cloud for collaborative training on combined compute resources. https://www.fedml.ai/cheetah
FedML Federated Model Serving Platform: Model as a service (MaaS) for diverse AI verticals, powered by federated model inference via geo-distributed cloud computing resource https://www.fedml.ai/modelServing
AI by the community for the community: Enable monetization of data, compute, and ML models https://www.fedml.ai/web3
About FedML Inc.
FedML (https://fedml.ai) provides an open-source community and an enterprise platform for decentralized and collaborative AI anywhere (at the edge or over the cloud) at any scale. More specifically, FedML provides an MLOps ecosystem that enables training, deployment, monitoring, and continual improvement of machine learning models anywhere (edge/cloud), while empowering collaboration on combined data, models, and computing resources in a privacy-preserving manner. FedML’s platform is backed by a large open-source community (top ranking GitHub library on federated learning), and its enterprise platform is currently used by 2000+ developers and 10+ enterprise customers worldwide. FedML’s AI application ecosystem also supports a large range of AI+ verticals, including but not limited to AIoT + Computer Vision, Generative AI, Health and Life Sciences, BioTech, Smart Home and Smart City, Retail Solution, Logistics, and FinTech.