
ScaleLLM: Unlocking Llama2-13B LLM Inference on Consumer GPU RTX 4090, powered by FEDML Nexus AI
- Motivation
- System Design
- Performance Evaluation
- Introducing a metric for LLM inference on Low-end GPU
- Performance on RTX 4090 v.s. vLLM on A100
- Performance of Multi-Services on Single A100
- Performance on L4 and T4
- FEDML Nexus AI Serverless Model Endpoint: Serving LLM on decentralized spot GPU instance
- Unlock AI x Blockchain: 10x cheaper than AWS, harvesting the idle time of decentralized gamer GPUs
- Future Works
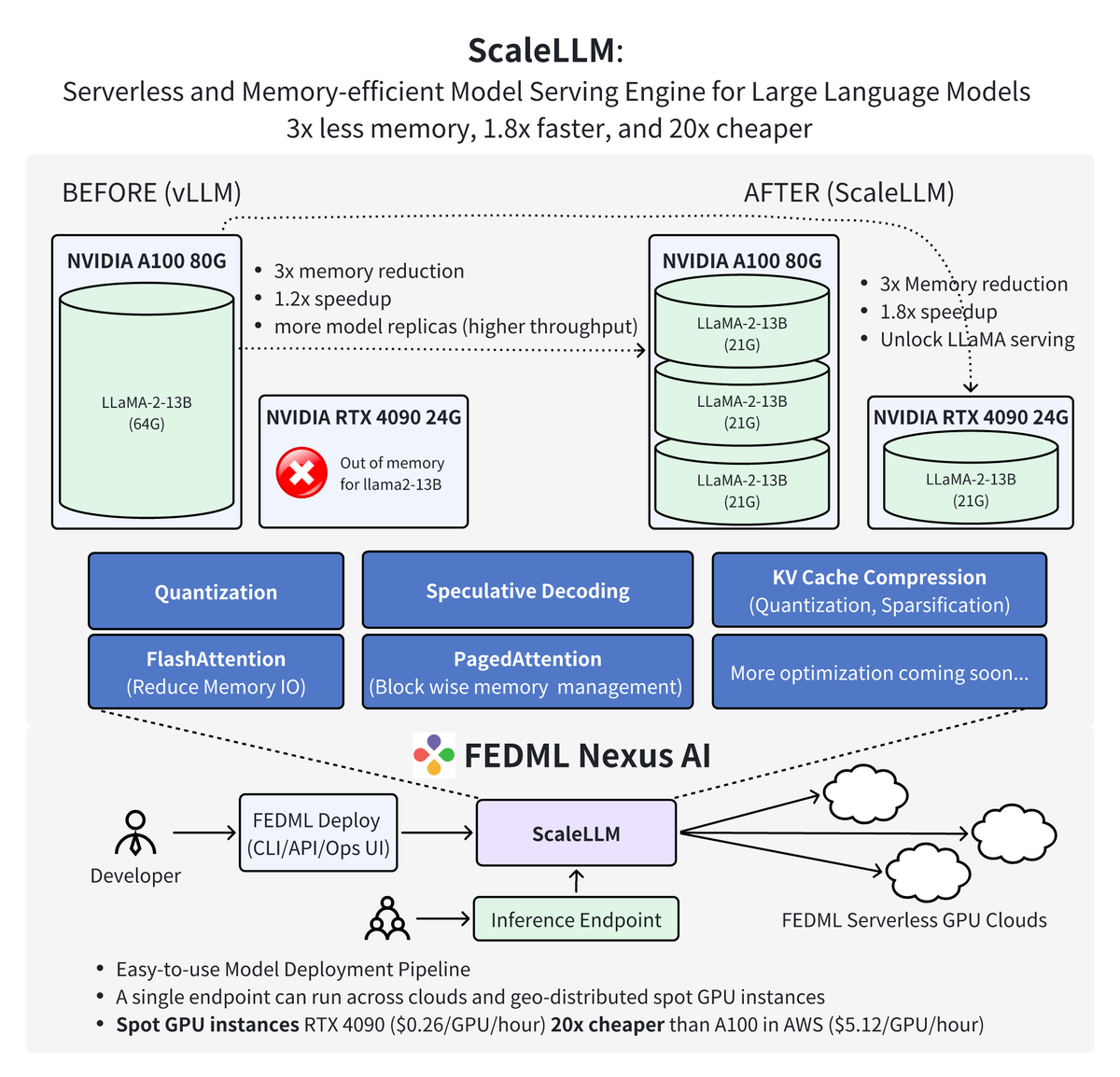
FEDML is thrilled to announce a significant milestone and a new era in Generative AI technology. We are excited to introduce ScaleLLM, a serverless and memory-efficient model serving engine for large language models (LLMs). With industrial-grade design and optimization of model inference techniques, including weight quantization, KV Cache quantization, fast attention, and fast decoding, ScaleLLM has achieved the following remarkable results:
- ScaleLLM can now host one LLaMA-2-13B-chat inference service on a single NVIDIA RTX 4090 GPU. The inference latency is up to 1.88 times lower than that of a single service using vLLM on a single A100 GPU.
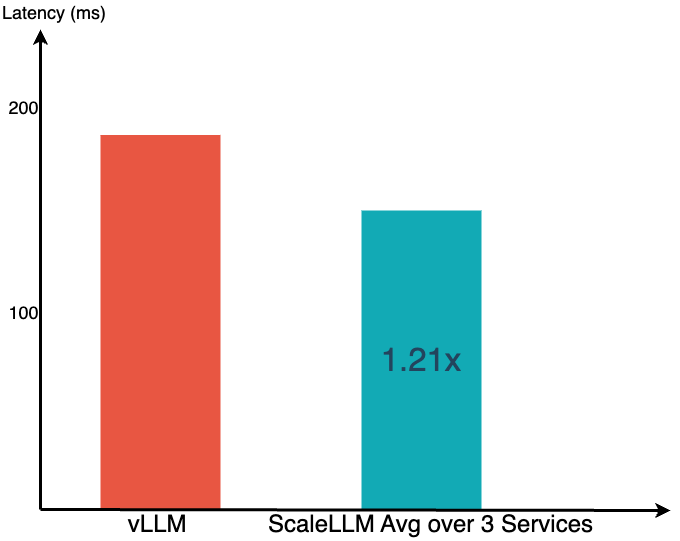
- ScaleLLM can now host three LLaMA-2-13B-chat inference services on a single A100 GPU. The average inference latency for these three services is 1.21 times lower than that of a single service using vLLM on a single A100 GPU.
- In response to the demand for generating the first token after a prompt within 1 second, ScaleLLM has successfully migrated the inference service for LLaMA-2-13B-chat to a single L4 or T4 GPU. Such a fast response time can significantly improve the quality of experience for the end users.
These achievements demonstrate the advanced capability of ScaleLLM in reducing the cost of LLM inference to 20x cheaper than A100 on AWS.
Thanks to the memory optimization offered by ScaleLLM, developers can now smoothly deploy AI models across a decentralized network of consumer-grade GPUs. To facilitate this, we further introduce the FEDML Nexus AI platform (https://fedml.ai). Nexus AI delivers comprehensive APIs, CLIs, and a user-friendly operational UI, empowering scientists and engineers to scale their model deployments on decentralized on-demand instances. Notably, these deployed endpoints can span multiple GPU instances, complete with failover and fault-tolerance support.
ScaleLLM, in conjunction with the Nexus AI platform, marks a paradigm shift in the methodology of AI model deployment. It equips developers with the ability to seamlessly deploy AI models across a decentralized network of consumer-grade GPUs, including models such as RTX 4090 and RTX 3090. Beyond the computational efficiency this approach offers, it also provides significant cost advantages, being 20 times more economical compared to similar services like AWS. This blend of functionality and affordability positions it as a revolutionary force in the AI deployment arena.
Motivation: Shortages and Availability of GPUs
The global semiconductor shortage in conjunction with the LLM/GenAI boom demonstrated a significant increase in computing demand, resulting in diminishing GPU availability. While some GPUs, particularly those in the high-end range, have experienced supply constraints, others, such as lower-end models, have remained relatively unaffected. One of the most notable examples of a GPU shortage is the A100, NVIDIA's high-performance accelerator. Due to its specialized capabilities, the A100 is in high demand among research institutions and data centers. However, supply chain disruptions have limited the production of A100 GPUs, leading to extended lead times and higher prices. Thus, given the shortage of A100 GPUs, we should improve the utility of a single A100 GPU with as many services as possible.
In contrast to the A100, lower-end GPUs like the RTX 4090, L4, T4, and other gaming GPUs have not experienced the same level of shortage. As a result, we argue that low-end GPUs with limited memory are the hidden treasure of the LLM community. Collaborated with Theta Network, we can have over 4K geo-distributed GPUs with memory varying from 4G to 24G.
The purpose of ScaleLLM is to design a user-friendly LLM inference library focusing on limited memory settings, including multiple services on a single A100 and single service on low-end GPUs.
System Design
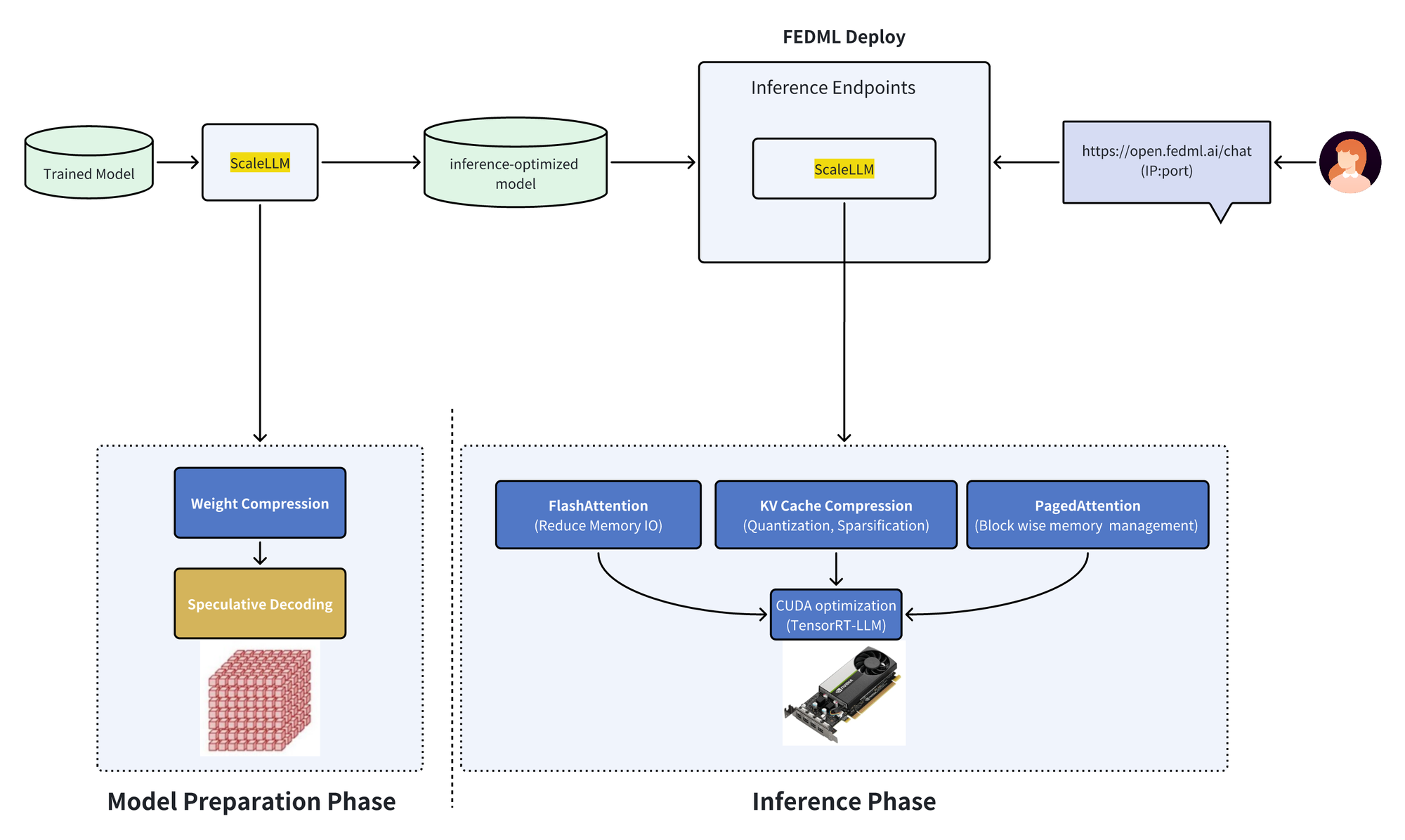
This content is only supported in a Lark DocsScaleLLM aims to integrate the majority of advanced LLM inference techniques into one user-friendly library. We summarize the techniques in the above diagrams. For a given LLM, we start with weight compression to reduce the memory footprint of the model itself. Next, we have an option to select FEDML's own compact LLMs for speculative decoding. After the model preparation phase, we have four major optimizations in inference: (1) FlashAttention for fast prompt ingestion with reduced memory IO, (2) KV cache compression that quantizes the KV cache vectors into low bits or sparsifying the stored tokens, (3) PagedAttention for better memory management in a block-wise manner, (4) the CUDA level optimization with TensorRT-LLM. The innovation of ScaleLLM comes from the industrial-grade design and optimization of these model inference techniques into a single library, as well as server GPU scheduling provided by FEDML Nexus AI (https://nexus.fedml.ai).
Performance Evaluation
Performance on RTX 4090 v.s. vLLM on A100
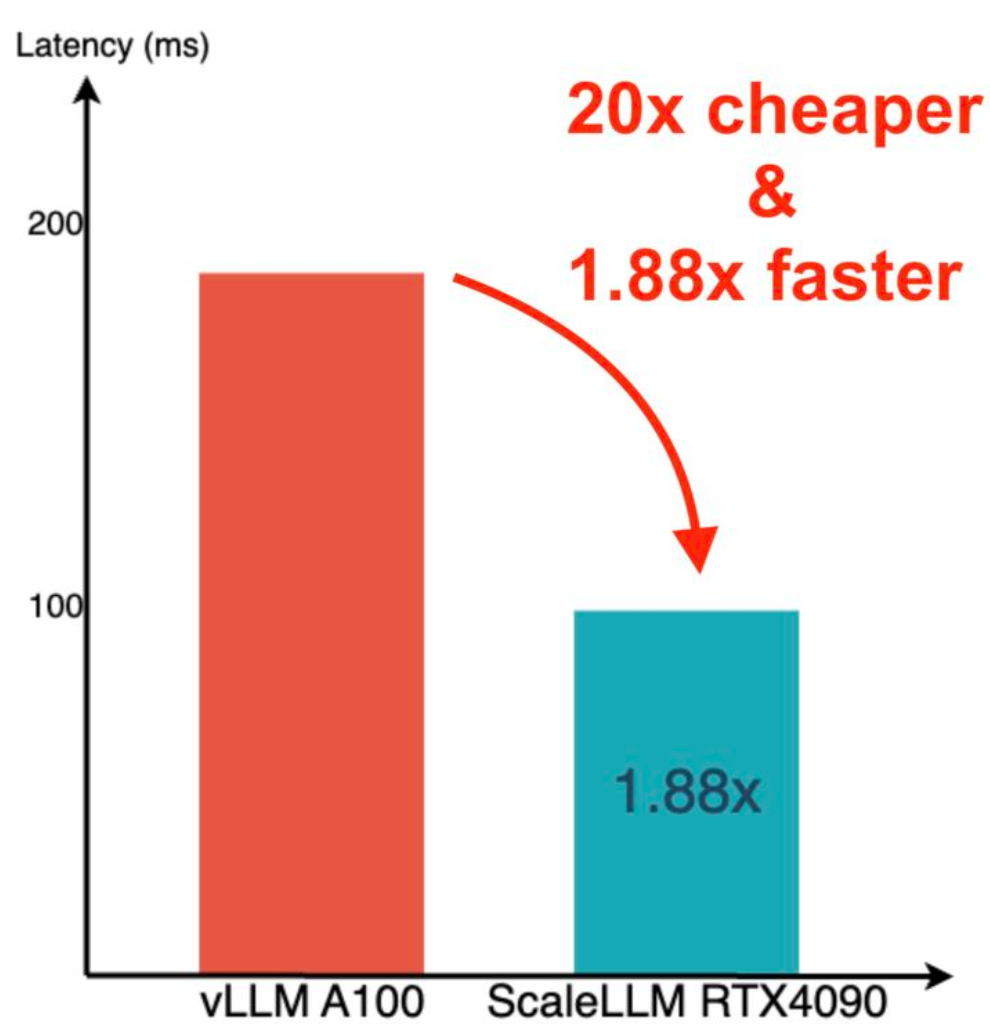
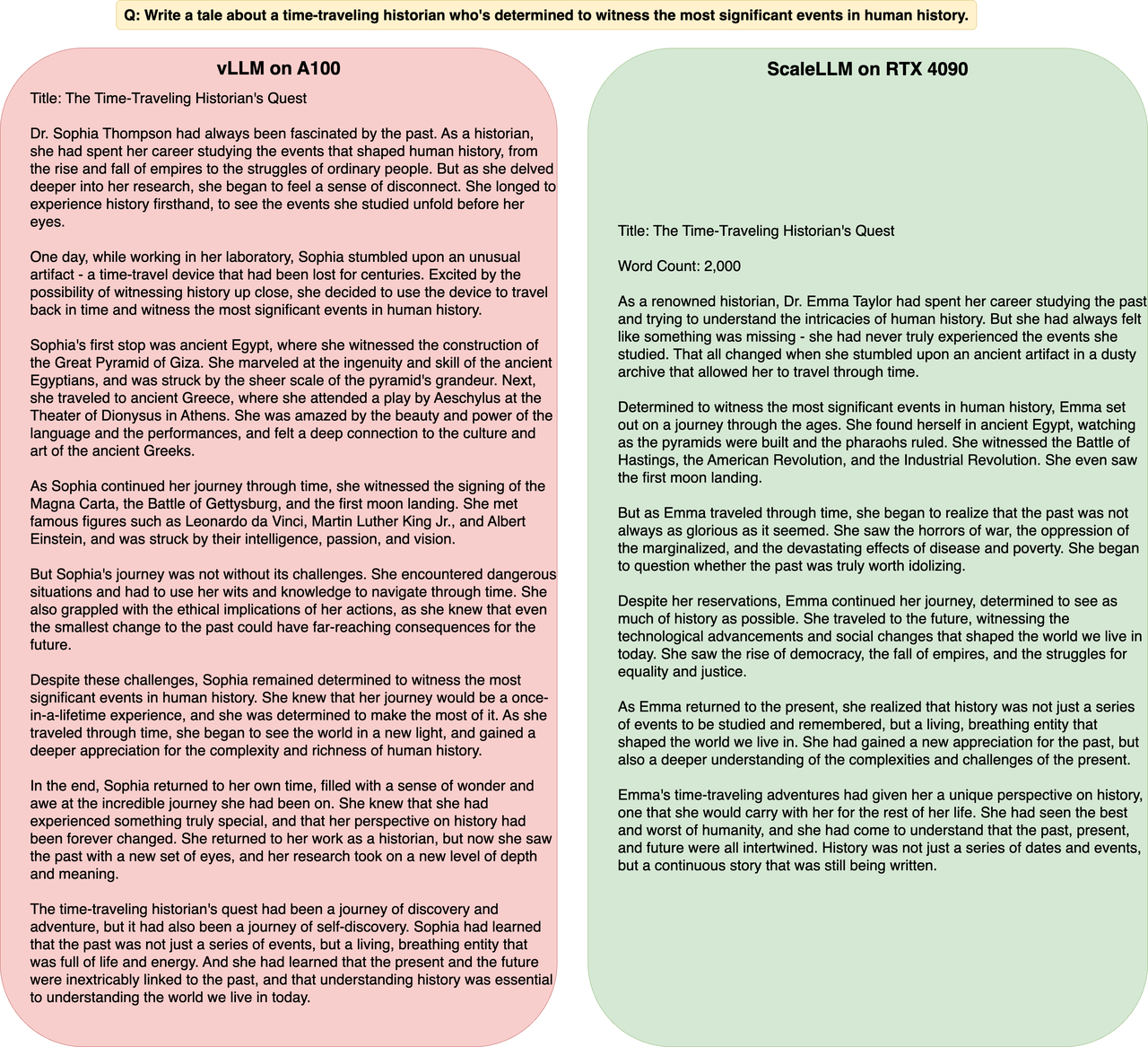
We test ScaleLLM on a single NVIDIA RTX 4090 GPU for Meta's LLaMA-2-13B-chat model. We focus on measuring the latency per request for an LLM inference service hosted on the GPU. We use the prompts from FlowGPT for evaluation, making the total required sequence length to 4K. To maintain a service at a single RTX 4090 GPU, we suggest 8-bit quantization on the weight and 8-bit quantization on the KV cache. We also introduce FP8 matrix multiplication for speedup. The implementation also contains FlashAttention and PagedAttention. We measure the latency when LLM generates the first token given the long context prompt. We show that ScaleLLM achieves up to 1.88x speedup in inference latency compared to vLLM implementation on a single A100 GPU.
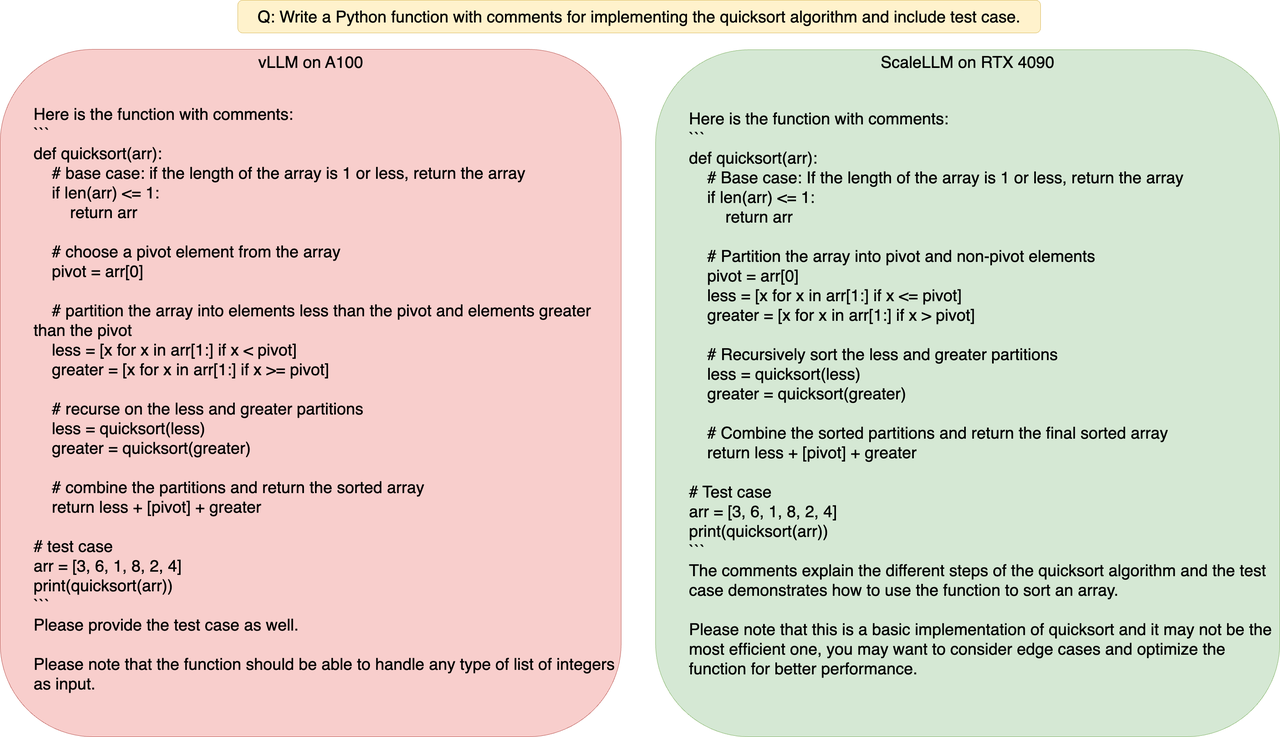
Example Prompt and Generation Result
Though compressed, the model quality doesn't degrade. Some examples of the token generation results are as follows.

Performance of Multi-Services on Single A100
We test ScaleLLM on a single NVIDIA A100 80G GPU for Meta's LLaMA-2-13B-chat model. We focus on measuring the latency per request for an LLM inference service hosted on the GPU. We use the prompts from FlowGPT for evaluation, making the total required sequence length to 4K. To maintain multiple services at a single A100 GPU, we suggest 4-bit quantization on the weight and 8-bit quantization on the KV cache. The implementation also contains FlashAttention and PagedAttention. We measure latency when LLM generates the first token given the long context prompt. We show that ScaleLLM can maintain up to 3 independent LLM services on a single A100 GPU. Moreover, the average inference latency is 1.21x faster than vLLM implementation, which can only support 1 service in A100 on FP16.
A Metric for LLM Inference on Low-End GPU (RTX 4090/L4/T4)
# Latency = Wall-clock latency in second for ingesting the prompt and generating the first token.
# Threshold = Latency constraint.
# Price = Average price for renting a single GPU server for a hour in cloud vendors
# Num.Services = Number of services hosted by the GPU.
We propose an economic score, which contains two folds.
- Latency<Threshold
- Score=Num.Services/(Latency*Price)
In other words, given a requirement for latency in serving an LLM model. We propose measuring how we squeeze more out of one single GPU by the score. The lower the GPU price, the more services on a single GPU, the more benefits we can have at a higher score.
Comparison on Low-End GPUs (NVIDIA L4/T4)
We extend ScaleLLM to more low-end GPUs, including NVIDIA L4 and T4. We still focus on measuring the latency per request for an LLM inference service hosted on the GPU. We use the prompts from FlowGPT for evaluation, making the total required sequence length to 4K. Since NVIDIA L4 has 24G memory, ScaleLLM can perform 8-bit quantization on the weight and 8-bit quantization on the KV cache. The implementation also contains FlashAttention and PagedAttention. For NVIDIA T4 GPU, ScaleLLM has to perform 4-bit quantization on the weight and 8-bit quantization on the KV cache due to memory limitation. ScaleLLM can fulfill the 1 second latency requirements by generating the first token after prompt. Moreover, the following table summarizes the economic score for each service. According to the table, we suggest hosting a 13B model service on a single RTX 4090 on the FEDML Nexus AI Platform.
GPU | Num. Services Per GPU | Platform | Score |
A100 | 1 | vLLM | 1.788348411 |
A100 | 1 | ScaleLLM | 3.409424471 |
A100 | 2 | ScaleLLM | 6.75725733 |
A100 | 3 | ScaleLLM | 6.495556906 |
L4 | 1 | ScaleLLM | 6.580409258 |
T4 (16G) | 1 | ScaleLLM | 1.140966926 |
RTX 4090 | 1 | ScaleLLM | 20.28360167 |
FEDML Nexus AI Serverless Model Endpoint: Serving LLM on decentralized spot GPU instance
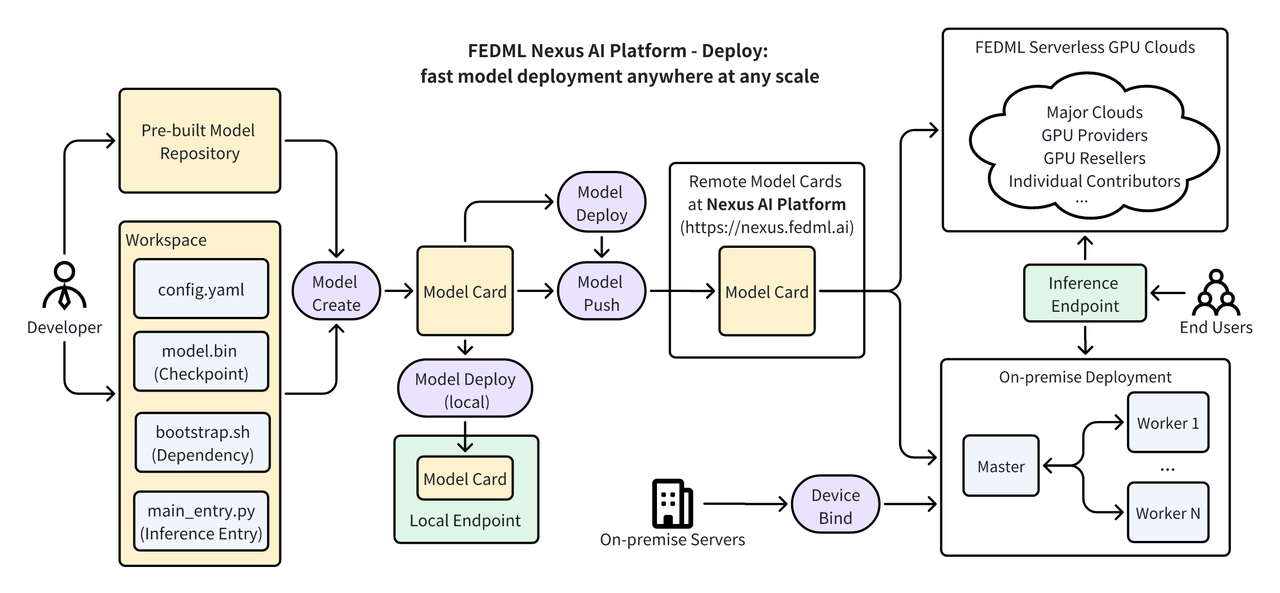
FEDML® Deploy provides end-to-end services for scientists and engineers to scale their models to the Cloud or On-Premise Servers quickly. From model management to model deployment, endpoint monitoring to model refinement, FEDML® Deploy provides open-box APIs / CLIs / UI to bring the models into industrial-level production.
Prerequisites
Install the FEDML library on your machine
pip install fedmlCreate a model from Hugging Face
Use fedml model create command to create a model. For options, use -n to indicate the model card name, then use -m to indicate a pre-built model.
In this quick start example, we will try to deploy an meta-llama/Llama-2-13b model from Hugging Face. To use a hugging face model, you will need to use hf: as the prefix of the model name. So the full model name is hf:meta-llama/Llama-2-13b.
fedml model create -n hf_model -m hf:meta-llama/Llama-2-13bDeploy the model to the local machine
Use fedml model deploy command to deploy the model. Use -n to indicate the model card name. To deploy to the local machine, use --local option.
fedml model deploy -n hf_model --localThe above command will:
- Automatically download and install the dependencies for inference.
- Download the model weights from Hugging Face.
- Start the model inference server and listen to localhost:2345/predict for requests.
Executing bootstrap script ...
Bootstrap start...
+ pip install langchain
...
Bootstrap finished
Bootstrap script is executed successfully!
INFO: Started server process [29013]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:2345 (Press CTRL+C to quit)Use a curl command to test the inference server.
curl -XPOST localhost:2345/predict -d '{"text": "Hello"}'You should see the output from the terminal with the response of that model.
"{'generated_text': '...'}"Deploy the model to Serverless GPU cloud
Before you start, you will need to create an account on FEDML Nexus AI Cloud. After you create an account, you will see an Account Key (API Key) from the profile page.
Next you need to bind your credit card to your account. This is required to use the GPU cloud.
Use fedml login $api_key to login to Nexus AI Cloud. Replace $api_key with your own API key.
fedml login $api_keyUse fedml model deploy command to deploy the model. Use -n to indicate the model card name.
fedml model deploy -n hf_modelFor more details, please read our documentation at https://doc.fedml.ai/deploy
Unlock AI x Blockchain: 20x cheaper than AWS, harvesting the idle time of decentralized consumer GPUs
Thanks to the memory reduction brought by ScaleLLM, deploying and running LLM such as LlaMA2-13B on a blockchain network becomes a reality. Now the intersection of AI and blockchain is not just a concept. It signifies a transformative approach to AI model deployment, where developers can seamlessly deploy AI models using a decentralized network of consumer GPUs. Next, we introduce the FEDML Nexus AI platform and see how it works with ScaleLLM to unlock AI x Blockchain.
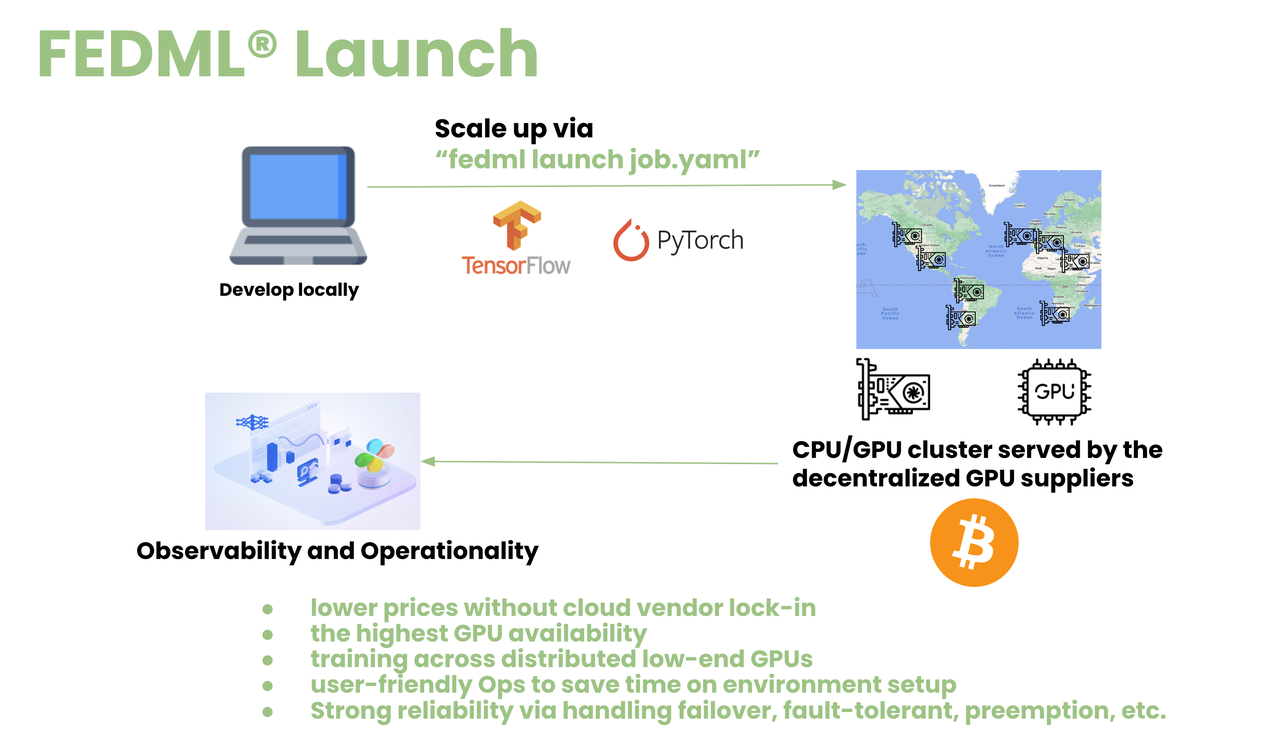
Figure: Scheduling a model deployment job into the decentralized GPU network
After installing the FEDML library (https://github.com/FedML-AI), an AI developer can initiate a model deployment by the operational workflow introduced in the previous section. Essentially, the underlying "fedml launch" command can schedule the job to run on a decentralized GPU network, thereby leveraging the computational power of numerous GPUs scattered across this network. The decentralized nature of this process significantly improves the efficiency and scalability of model deployment, enabling developers to tap into a vast, underutilized resource pool.
Figure: User in FEDML Nexus AI Platform received an AI job and gets rewarded
The above figure shows an example where a user in FEDML Nexus AI Platform received an AI job and got rewarded. Blockchain's decentralized nature aligns perfectly with the requisite infrastructure, ensuring a secure, reliable, and transparent operation. Contributors to the blockchain not only maintain the integrity of the network but also play a crucial role in facilitating the large-scale computational tasks required for AI model deployment.
Future Works
We would like to release more innovative algorithms to further accelerate the inference latency of LLM with over 13B parameters on low-end GPUs. Moreover, we would like to release FEDML's own compact and powerful LLMs for extreme long-context inference.