
Scalable Model Deployment and Serving on FEDML Nexus AI
FEDML Nexus AI - Your GenAI Platform at Scale - provides a full-stack of GenAI model service capabilities such as model deployment, inference, training, AI Agent, GPU job scheduling, multi-cloud/decentralized GPU management, experiment tracking, and model service monitoring. In this article, we introduce how FEDML model deployment and serving work.
Five-layer Model Serving Architecture
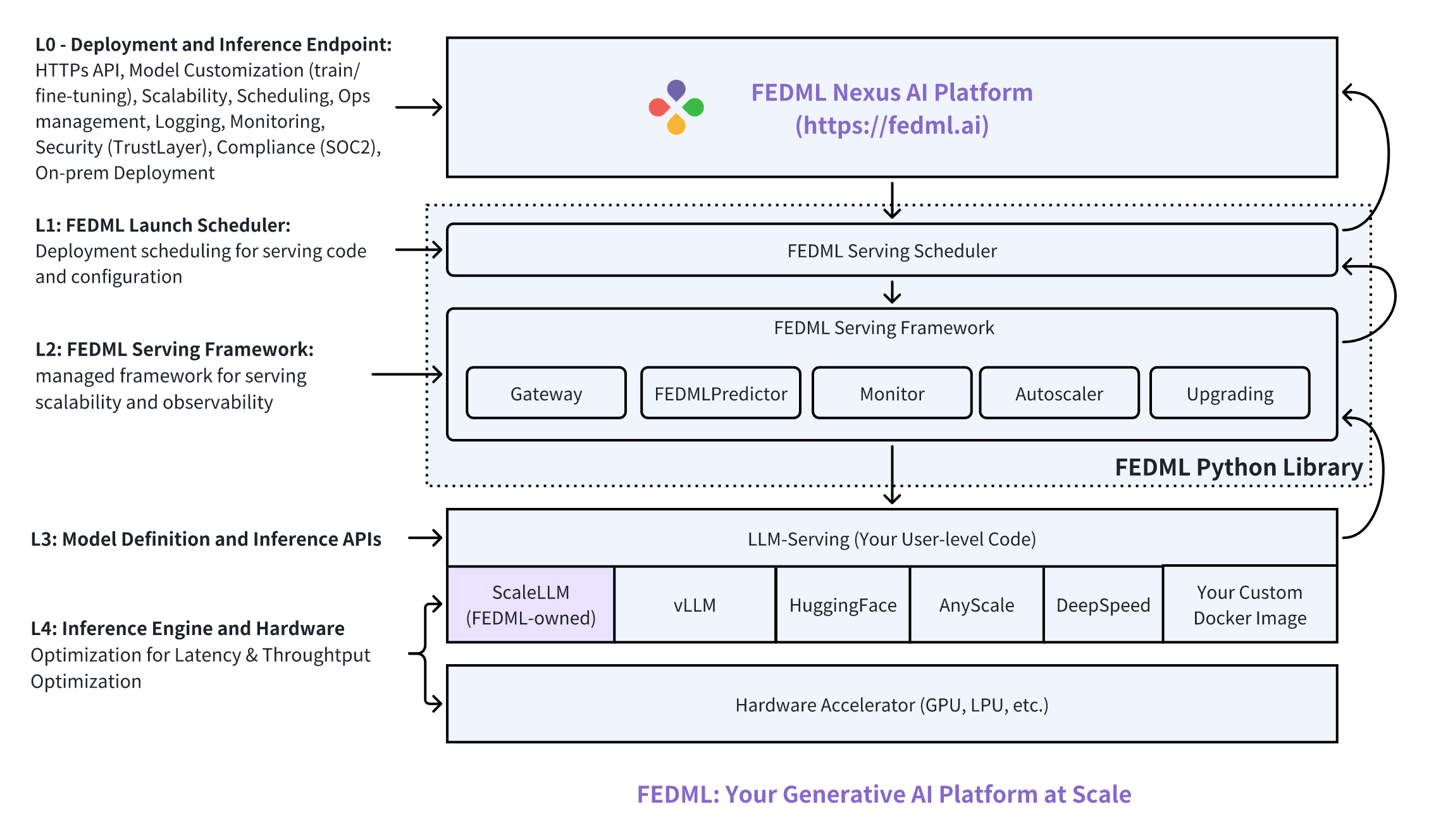
Figure 1: Overview of FEDML model deployment and serving
The figure above shows FEDML Nexus AI's perspective of model inference service. It's divided into a 5-layer architecture:
- Layer 0 (L0) - Deployment and Inference Endpoint. This layer enables HTTPs API, model customization (train/fine-tuning), scalability, scheduling, ops management, logging, monitoring, security (e.g., trust layer for LLM), compliance (SOC2), and on-prem deployment.
- Layer 1 (L1) - FEDML Launch Scheduler. It collaborates with the L0 MLOps platform to handle deployment workflow on GPU devices for running serving code and configuration.
- Layer 2 (L2) - FEDML Serving Framework. It's a managed framework for serving scalability and observability. It will load the serving engine and user-level serving code.
- Layer 3 (L3) - Model Definition and Inference APIs. Developers can define the model architecture, the inference engine to run the model, and the related schema of the model inference APIs.
- Layer 4 (L4): Inference Engine and Hardware. This is the layer many machine learning system researchers and hardware accelerator companies work to optimize the inference latency & throughput. At FEDML, we've developed our in-house inference library ScaleLLM (https://scalellm.ai)
Distributed/Cross-cloud Model Endpoint
One of the unique features in FEDML Nexus AI model serving is that a single endpoint can run across geo-distributed GPU clouds. It further scales AI Agents by enabling distributed vector DB. Such a system can provide a range of benefits, from improved reliability to better performance:
- Increased Reliability and Availability. By spreading resources across multiple clouds, developers can ensure that if one provider experiences downtime, the model service can still run on the other providers. Automated failover processes ensure that traffic is redirected to operational instances in the event of a failure.
- Scalability. Cloud services typically offer the ability to scale resources up or down. Multiple providers can offer even greater flexibility and capacity. Distributing the load across different clouds can help manage traffic spikes and maintain performance.
- Performance. Proximity to users can reduce latency. By running endpoints on different clouds, developers can optimize for geographic distribution. Different clouds might offer specialized GPU types that are better suited for particular types of workloads.
- Cost Efficiency. Prices for cloud services can vary. FEDML Nexus AI uses multiple providers allowing developers to take advantage of the best pricing models. Developers can bid for unused capacity at a lower price, which might be available from different providers at different times.
- Risk Management and Data Sovereignty. Distributing across different regions can mitigate risks associated with policy regulations affecting service availability. For compliance reasons, developers might need to store and process data in specific jurisdictions. Multiple clouds can help meet these requirements.
ScaleLLM: Serverless and Memory-efficient Model Serving Engine for Large Language Models
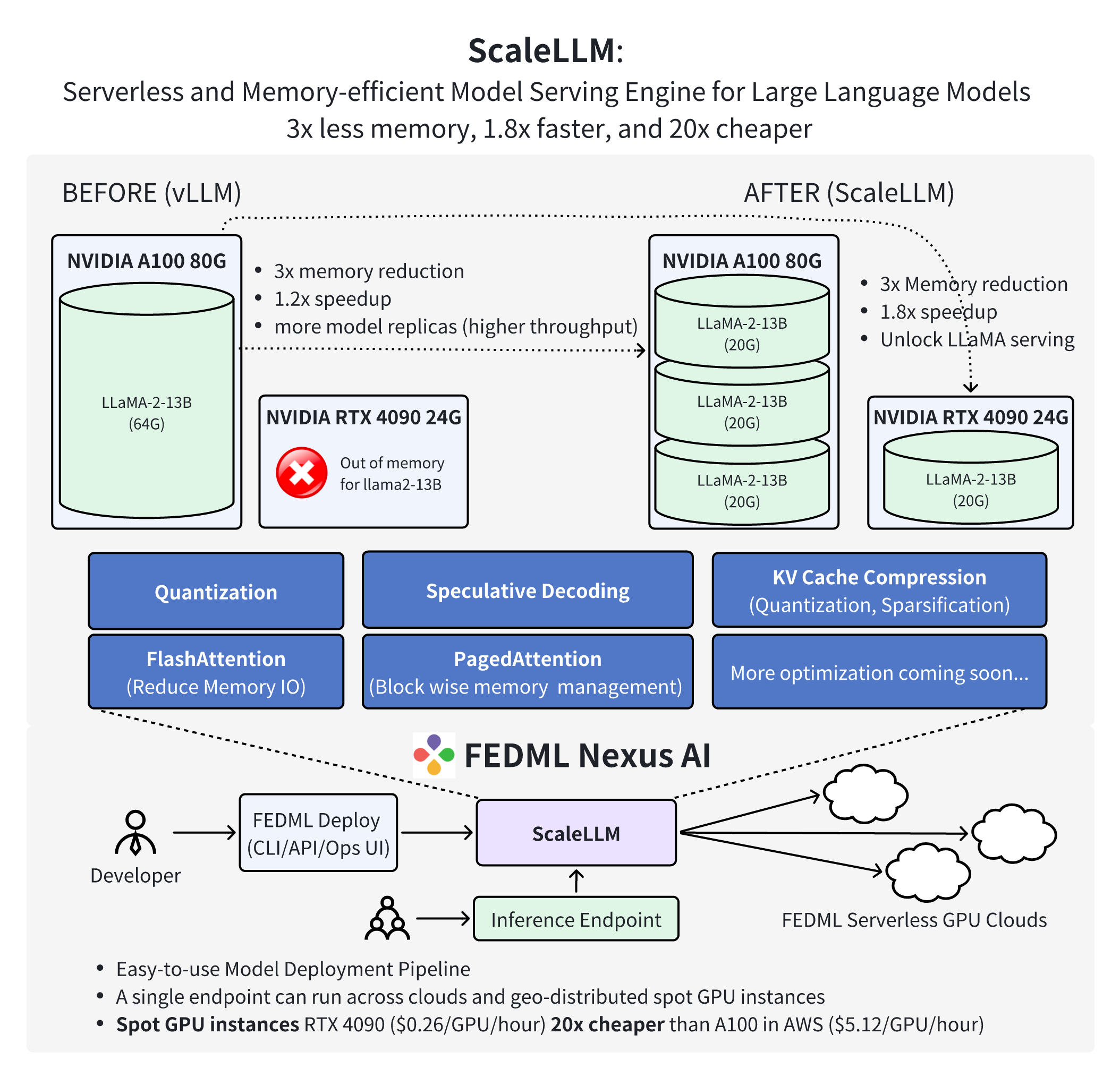
Figure 2: Overview of ScaleLLM
ScaleLLM is a serverless and memory-efficient model serving engine for large language models (LLMs). With industrial-grade design and optimization of model inference techniques, including weight quantization, KV Cache quantization, fast attention, and fast decoding, ScaleLLM has achieved the following remarkable results:
- ScaleLLM can now host one LLaMA-2-13B-chat inference service on a single NVIDIA RTX 4090 GPU. The inference latency is up to 1.88 times lower than that of a single service using vLLM on a single A100 GPU.
- ScaleLLM can now host three LLaMA-2-13B-chat inference services on a single A100 GPU. The average inference latency for these three services is 1.21 times lower than that of a single service using vLLM on a single A100 GPU.
- In response to the demand for generating the first token after a prompt within 1 second, ScaleLLM has successfully migrated the inference service for LLaMA-2-13B-chat to a single L4 or T4 GPU. Such a fast response time can significantly improve the quality of experience for the end users.
These achievements demonstrate the advanced capability of ScaleLLM in reducing the cost of LLM inference to 20x cheaper than A100 on AWS.
Thanks to the memory optimization offered by ScaleLLM, developers can now smoothly deploy AI models across a decentralized network of consumer-grade GPUs. To facilitate this, we further introduce the FEDML Nexus AI platform (https://fedml.ai). Nexus AI delivers comprehensive APIs, CLIs, and a user-friendly operational UI, empowering scientists and engineers to scale their model deployments on decentralized on-demand instances. Notably, these deployed endpoints can span multiple GPU instances, complete with failover and fault-tolerance support.
ScaleLLM, in conjunction with the Nexus AI platform, marks a paradigm shift in the methodology of AI model deployment. It equips developers with the ability to seamlessly deploy AI models across a decentralized network of consumer-grade GPUs, including models such as RTX 4090 and RTX 3090. Beyond the computational efficiency this approach offers, it also provides significant cost advantages, being 20 times more economical compared to similar services like AWS. This blend of functionality and affordability positions it as a revolutionary force in the AI deployment arena.
For more details, please read our blog: https://blog.fedml.ai/scalellm-unlocking-llama2-13b-llm-inference-on-consumer-gpu-rtx-4090-powered-by-fedml-nexus-ai/
Zero-code Serving: Pre-Built Models by Clicking "Deploy" Twice
- Find the Model and Click "Deploy"
- Select GPU Type and Click "Deploy"
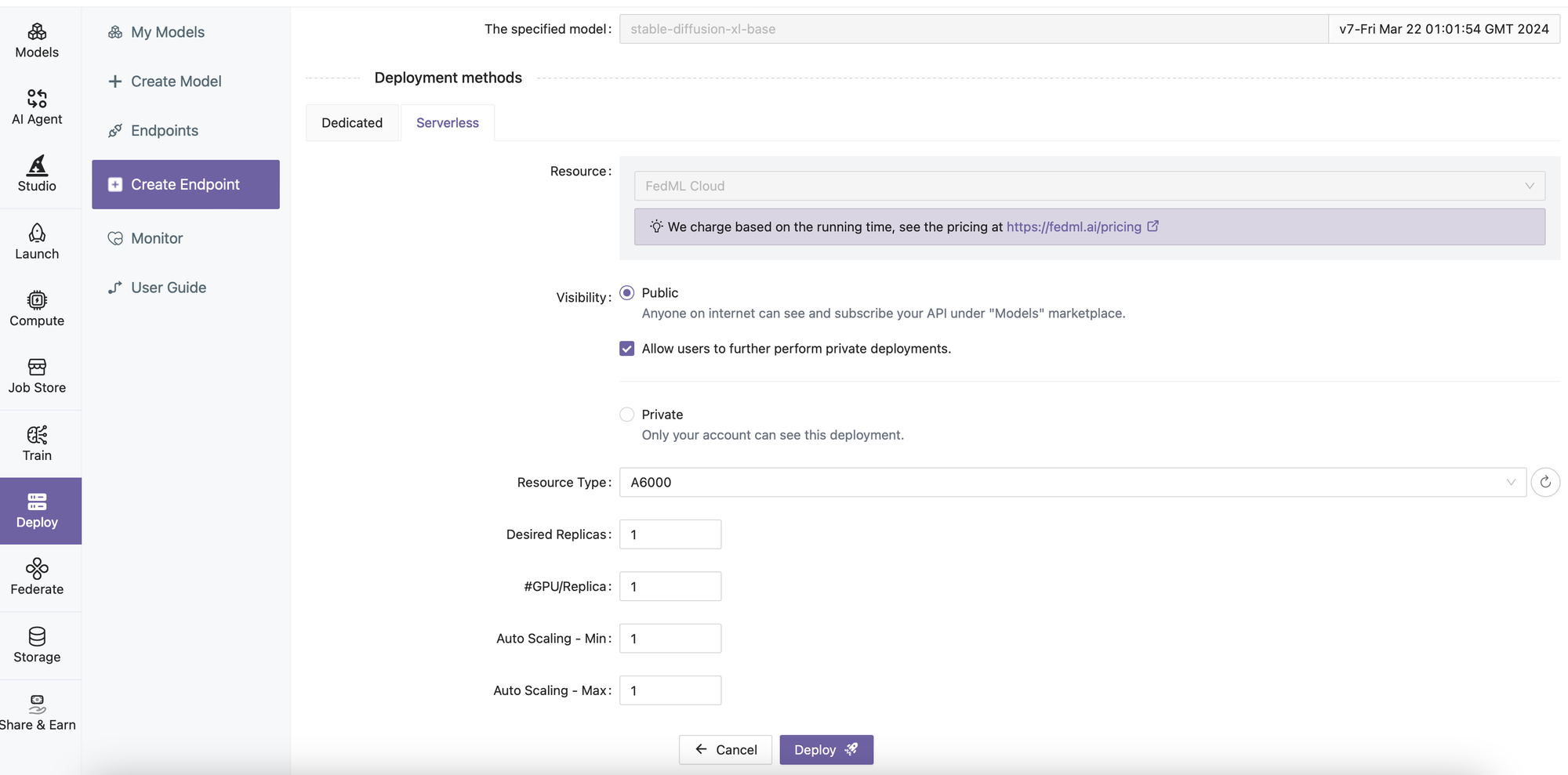
Quick Start: Serve Pre-built LLMs by Command Line and Dashboard
- Create a LLM model from Hugging Face
Use fedml model create command to create a model. For options, use -n to indicate the model card name, then use -m to indicate a pre-built model.In this quick start example, we will try to deploy an EleutherAI/pythia-70m model from Hugging Face. To use a hugging face model, you will need to use hf: as the prefix of the model name. So the full model name is hf:EleutherAI/pythia-70m.
fedml model create -n hf_model -m hf:EleutherAI/pythia-70m- Test the model on the local machine
Use fedml model deploy --local command to deploy the model on the current machine. Use -n to indicate the model card name.
fedml model deploy -n hf_model --local- Push the model to FEDML
Use fedml model push command to push the model. Use -n to indicate the model card name. Replace $api_key with your own API key.
fedml model push -n hf_model -k $api_key- Find Model on FEDML Dashboard
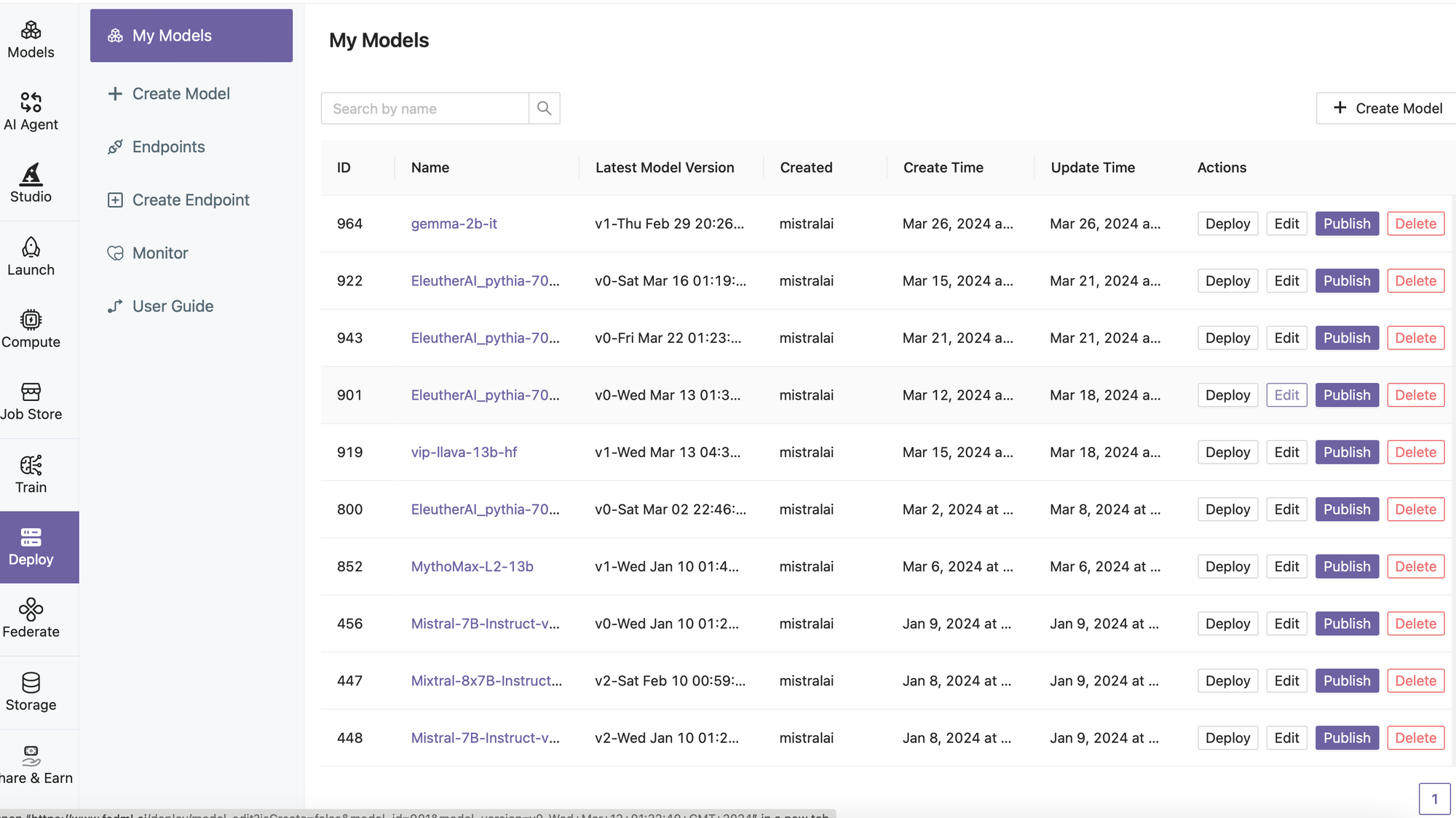
- Edit Model Information
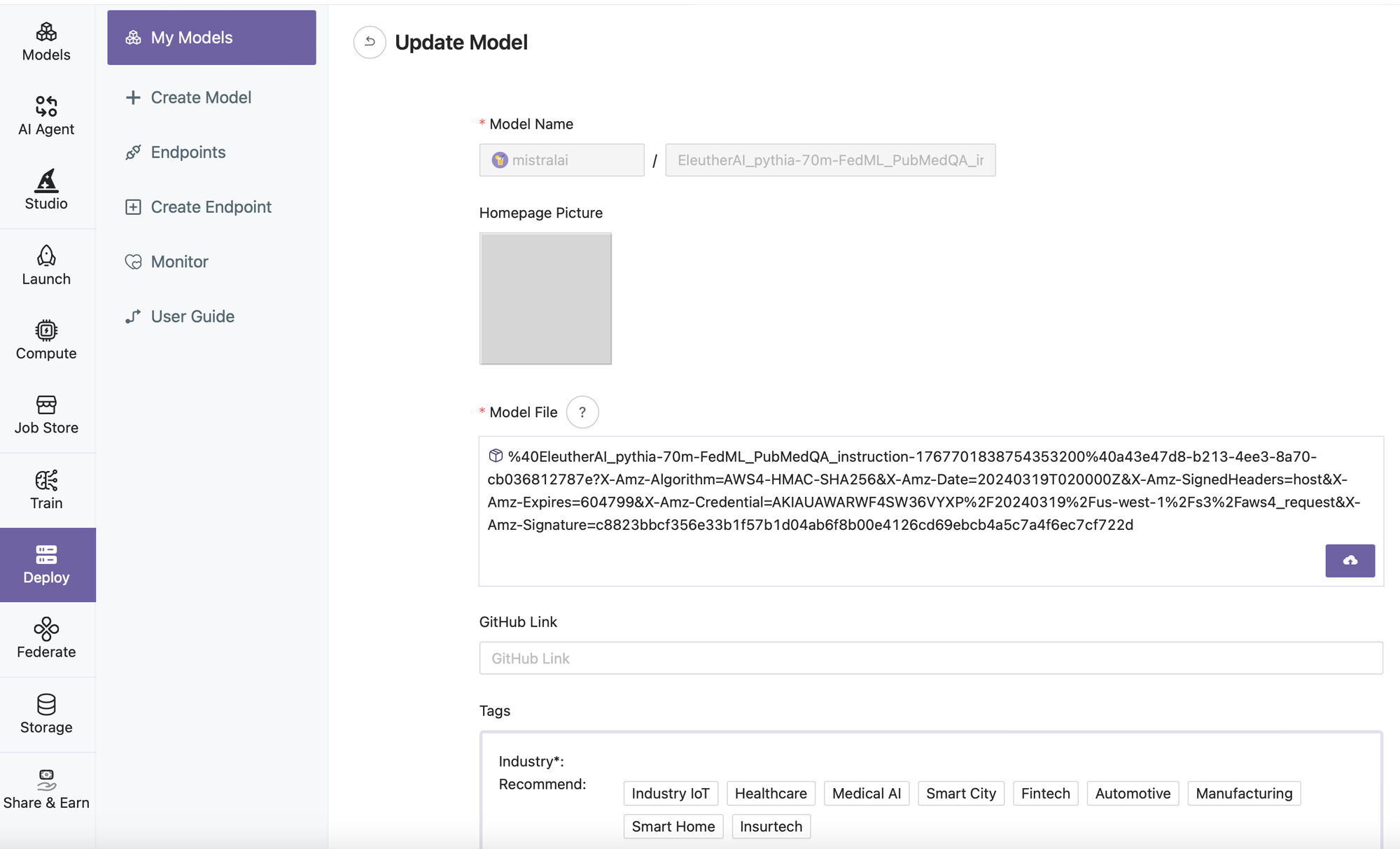
- Deploy the model to the Serverless GPU cloud
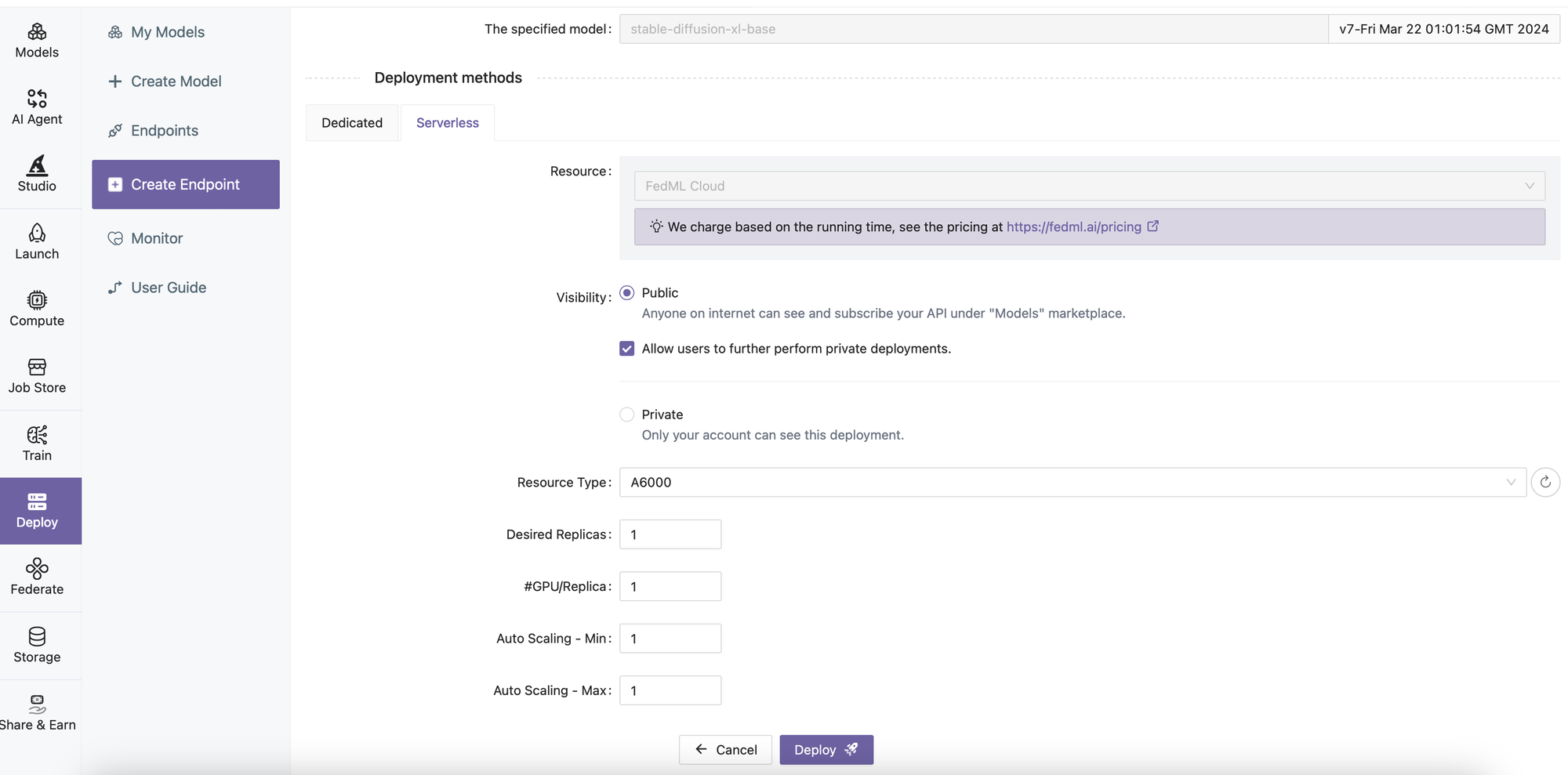
- Check the Endpoint Status
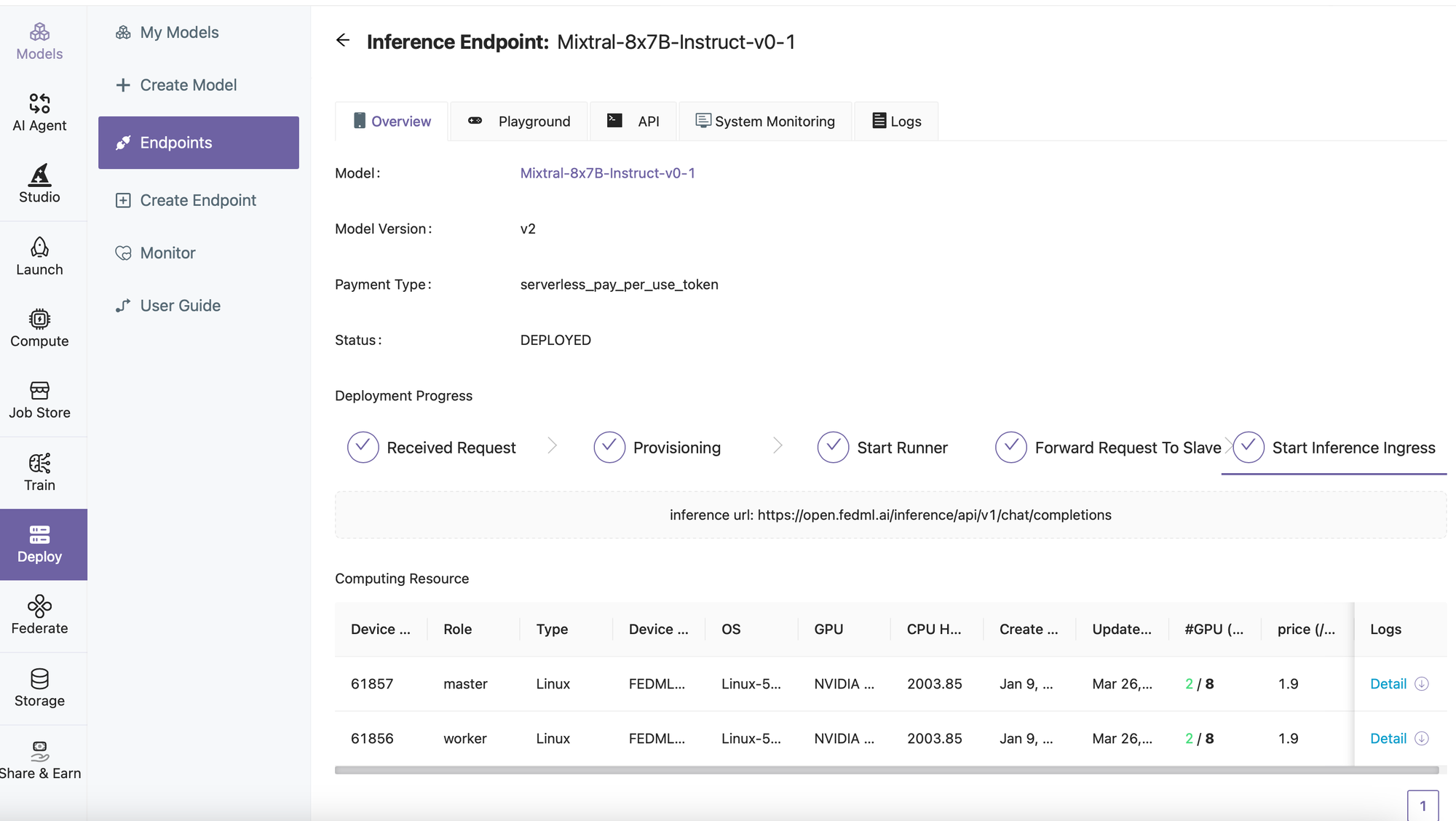
Further Advances: Customize, Deploy, and Scale
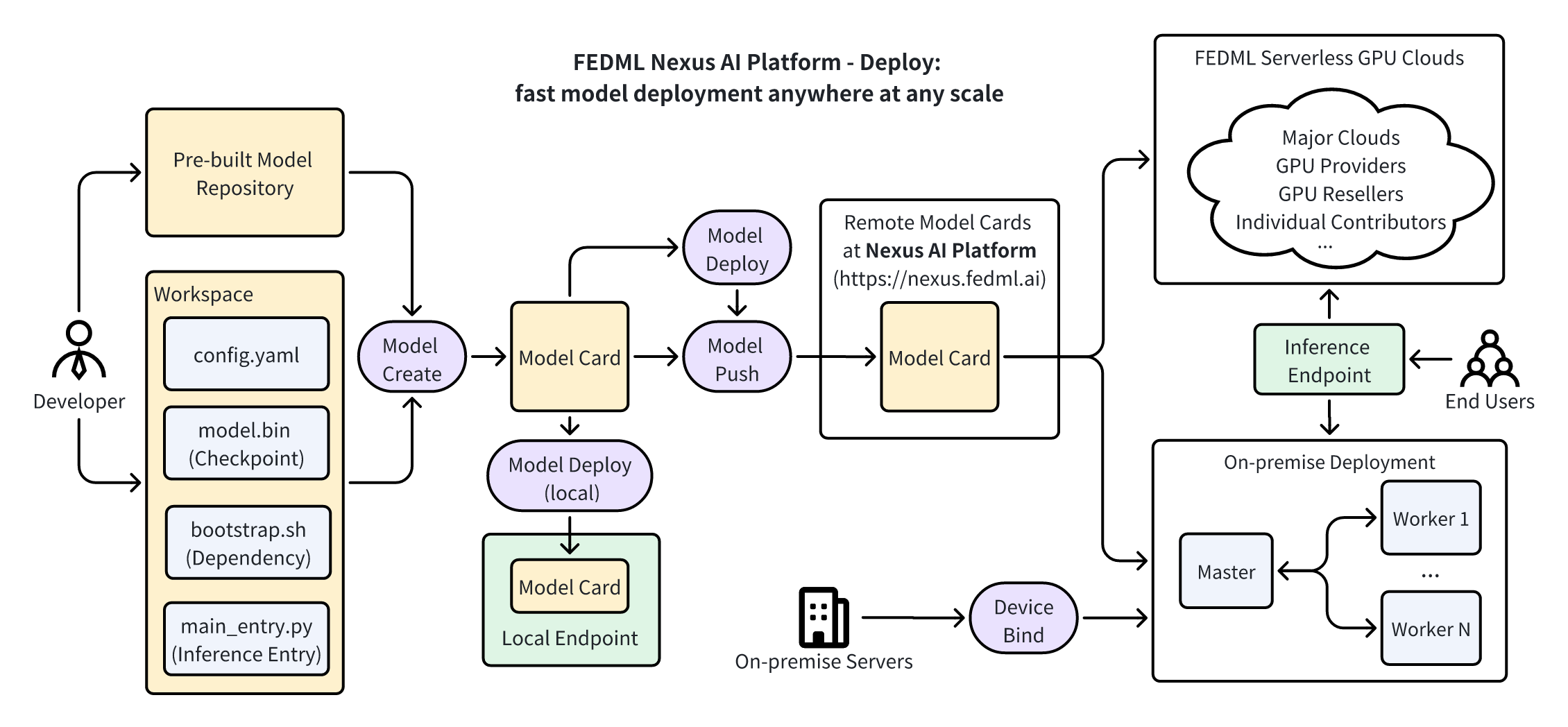
FEDML Nexus AI platform provides many further capabilities to customize, deploy, and scale any model. A specific deployment workflow is shown in the diagram above. Developers can deploy their custom docker image or just serve related Python scripts into FEDML Nexus AI platform for deployment in the distributed/decentralized GPU cloud. For detailed steps, please refer to https://doc.fedml.ai.
- Create Your Customized Model
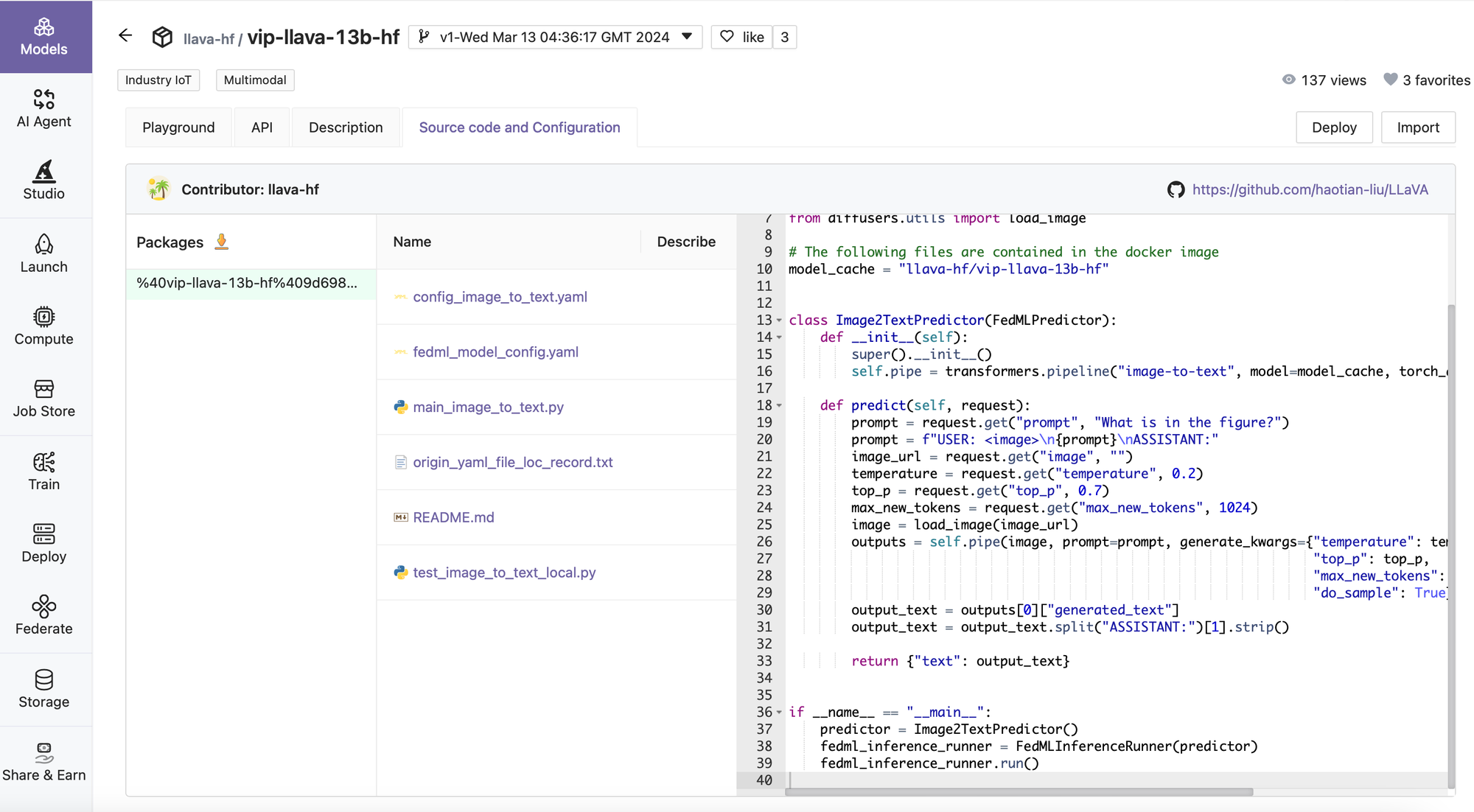
For more details, please see the FEDML documentation: https://doc.fedml.ai/deploy/create_model.
- Bring your own GPUs: Running a Single Model Endpoint across Geo-distributed GPUs
When allocating on-premise resources for a specific endpoint, we can select GPU workers across geo-distributed GPUs.
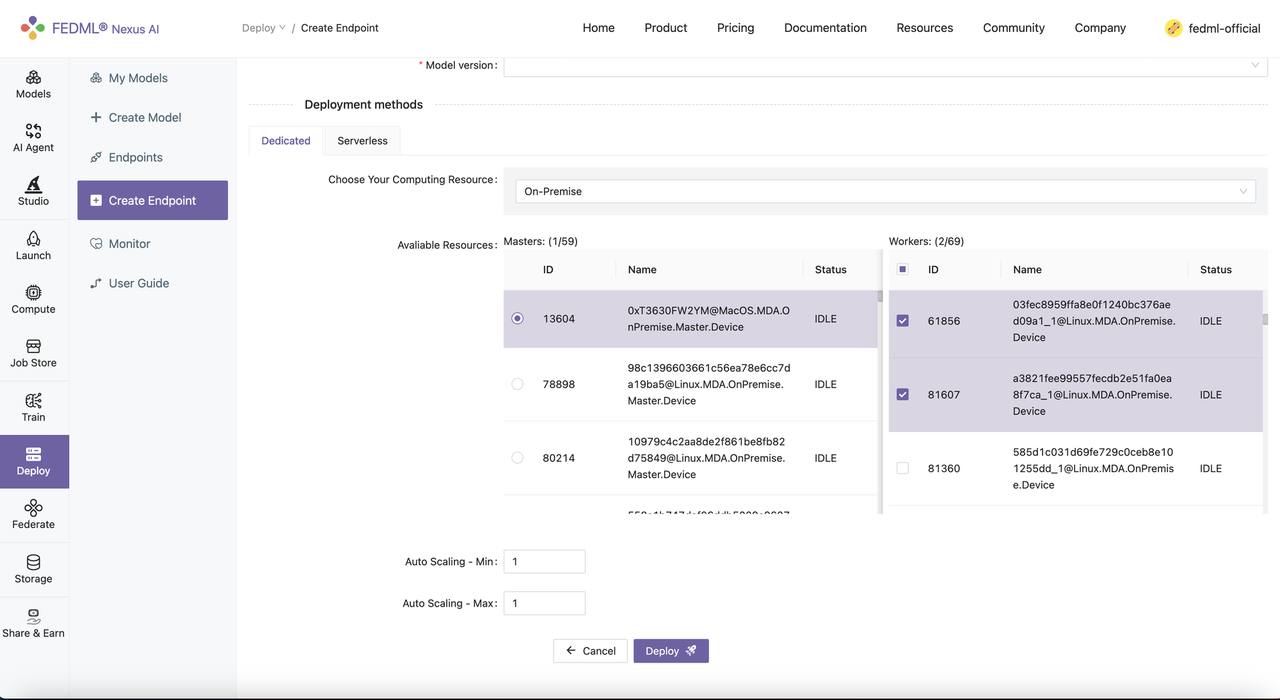
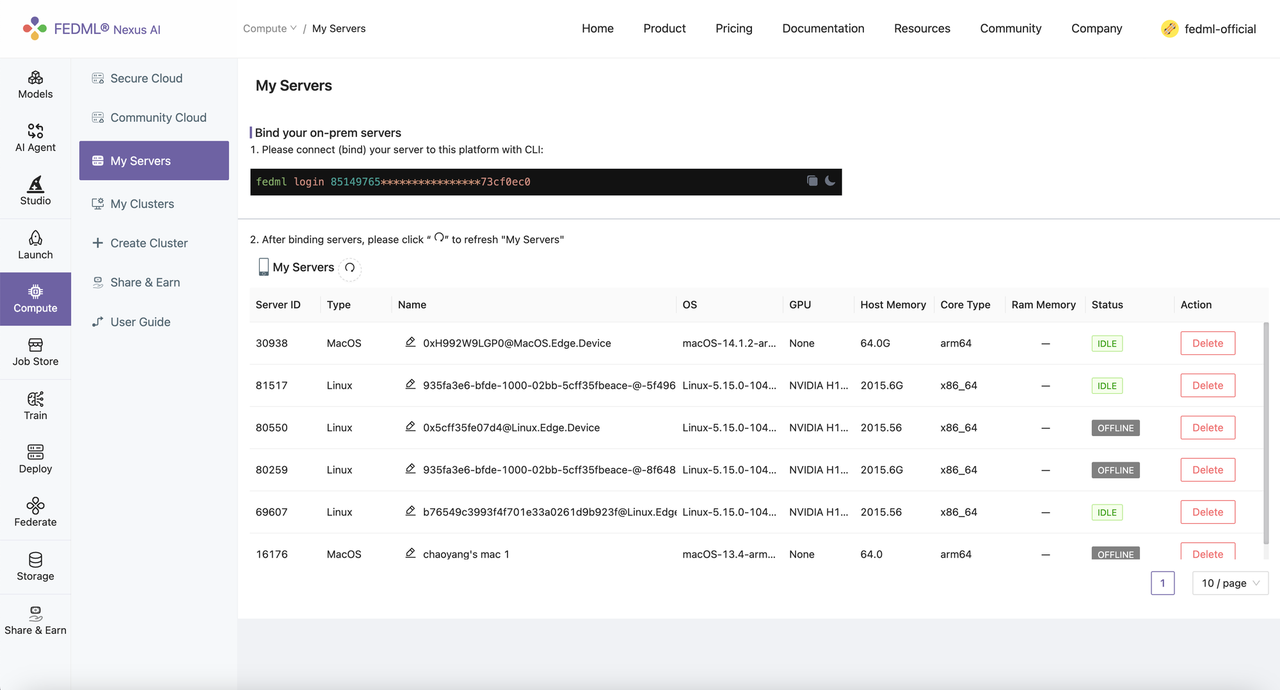
The geo-distributed GPUs can be binded by Compute -> My Servers with one-line command "fedml login <API key>". For more details, please see the FEDML documentation: https://doc.fedml.ai/deploy/deploy_on_premise
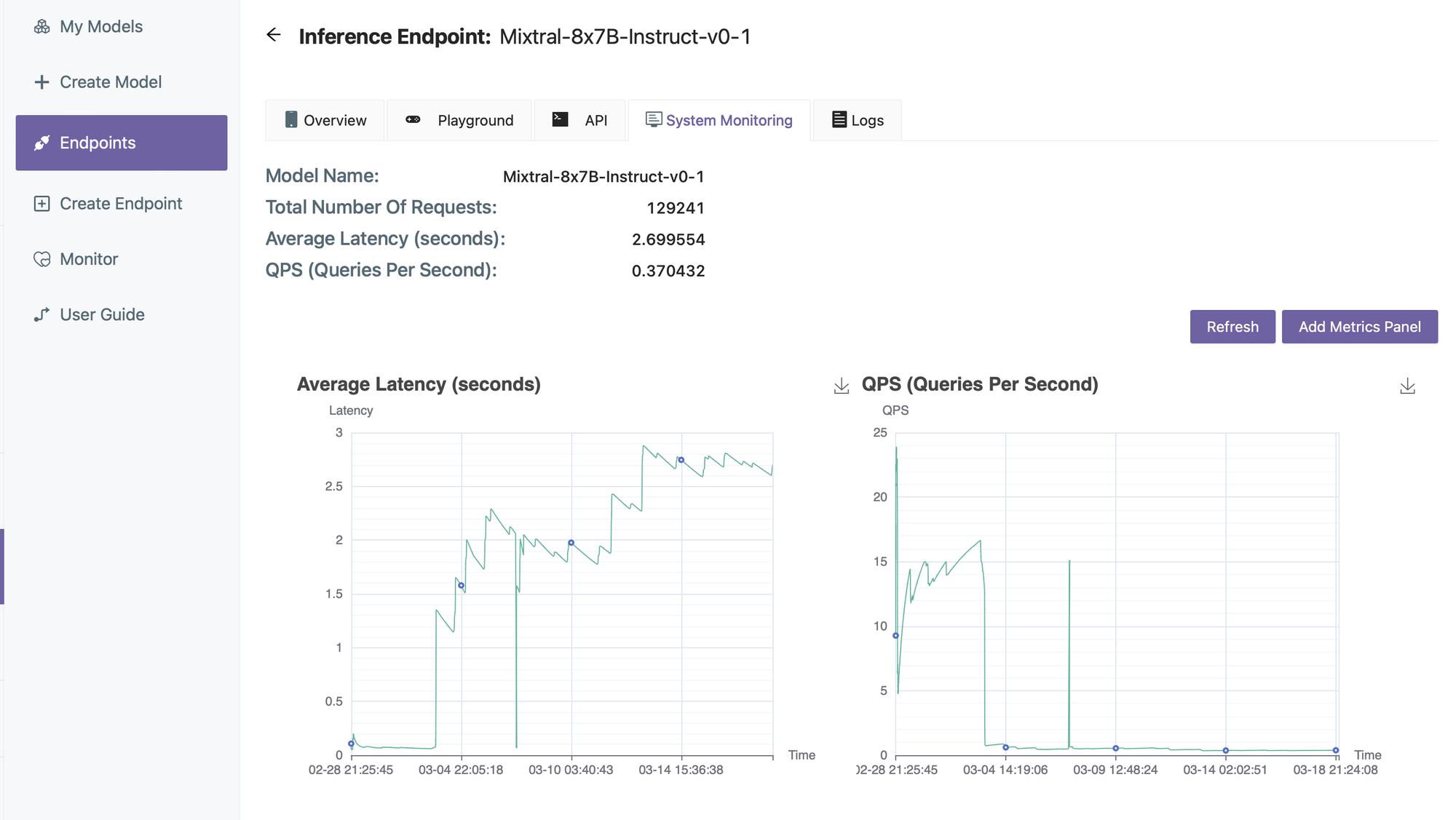
- Manage & Monitor Deployed Models
About FEDML, Inc.
FEDML is your generative AI platform at scale to enable developers and enterprises to build and commercialize their own generative AI applications easily, scalably, and economically. Its flagship product, FEDML Nexus AI, provides unique features in enterprise AI platforms, model deployment, model serving, AI agent APIs, launching training/Inference jobs on serverless/decentralized GPU cloud, experimental tracking for distributed training, federated learning, security, and privacy.
FEDML, Inc. was founded in February 2022. With over 5000 platform users from 500+ universities and 100+ enterprises, FEDML is enabling organizations of all sizes to build, deploy, and commercialize their own LLMs and Al agents. The company's enterprise customers span a wide range of industries, including generative Al/LLM applications, mobile ads/recommendations, AloT (logistics/retail), healthcare, automotive, and web3. The company has raised $13.2M seed round. As a fun fact, FEDML is currently located at the Silicon Valley "Lucky building" (165 University Avenue, Palo Alto, CA), where Google, PayPal, Logitech, and many other successful companies started.